Quick post and note to self today… Azure Security Center checks many of your resources for vulnerabilities or attacks. For a while now, it also does so for Azure Kubernetes Service (AKS). In my portal, I saw the following:
Attacked resources?!? Now what?
There are many possible alerts. These are the ones I got:
Some of the alerts for AKS in Security Center
The first one, for instance, reports that a container has mounted /etc/kubernetes/azure.json on the AKS worker node where it runs. That is indeed a sensitive path because azure.json contains the credentials of the AKS security principal. In this case, it’s Azure Key Vault Controller that has been configured to use this principal to connect to Azure Key Vault.
Another useful one is the alert for new high privilege roles. In my case, these alerts are the result from installing Helm charts that include such a role. For example, the helm-operator chart includes a role which uses a ClusterRoleBinding for [{“resources”:[“*”],”apiGroups”:[“*”],”verbs”:[“*”]}]. Yep, that’s high privilege indeed.
Remember, you will need Azure Security Center Standard for these capabilities. Azure Kubernetes Services is charged per AKS core at $2/VM core/month in the preview (according to what I see in the portal).
Security Center Standard pricing in preview for AKS
Be sure to include Azure Security Center Standard when you are deploying Azure resources (not just AKS). The alerts you get are useful. In most cases, you will also learn a thing or two about the software you are deploying! 😆
If you have followed my blog a little, you have seen a few posts about GitOps with Flux CD. This time, I am taking a look at Argo CD which, like Flux CD, is a GitOps tool to deploy applications from manifests in a git repository.
Don’t want to read this whole thing?
Here’s the video version of this post
There are several differences between the two tools:
At first glance, Flux appears to use a single git repo for your cluster where Argo immediately introduces the concept of apps. Each app can be connected to a different git repo. However Flux can also use multiple git repositories in the same cluster. See https://github.com/fluxcd/multi-tenancy for more information
Flux has the concept of workloads which can be automated. This means that image repositories are scanned for updates. When an update is available (say from tag v1.0.0 to v1.0.1), Flux will update your application based on filters you specify. As far as I can see, Argo requires you to drive the update from your CI process, which might be preferred.
By default, Argo deploys an administrative UI (next to a CLI) with a full view on your deployment and its dependencies
Argo supports RBAC and integrates with external identity providers (e.g. Azure Active Directory)
The Argo CD admin interface is shown below:
Argo CD admin interface… not too shabby
Let’s take a look at how to deploy Argo and deploy the app you see above. The app is deployed using a single yaml file. Nothing fancy yet such as kustomize or jsonnet.
Deployment
The getting started guide is pretty clear, so do have a look over there as well. To install, just run (with a deployed Kubernetes cluster and kubectl pointing at the cluster):
Next, install the CLI. On a Mac, that is simple (with Homebrew):
brew tap argoproj/tap
brew install argoproj/tap/argocd
You will need access to the API server, which is not exposed over the Internet by default. For testing, port forwarding is easiest. In a separate shell, run the following command:
You can now connect to https://localhost:8080 to get to the UI. You will need the admin password by running:
kubectl get pods -n argocd -l app.kubernetes.io/name=argocd-server -o name | cut -d'/' -f 2
You can now login to the UI with the user admin and the displayed password. You should also login from the CLI and change the password with the following commands:
Great! You are all set now to deploy an application.
Deploying an application
We will deploy an application that has a couple of dependencies. Normally, you would install those dependencies with Argo CD as well but since I am using a cluster that has these dependencies installed via Azure DevOps, I will just list what you need (Helm commands):
To know more about these dependencies and use an Azure DevOps YAML pipeline to deploy them, see this post. If you want, you can skip the externaldns installation and create a DNS record yourself that resolves to the public IP address of Nginx Ingress. If you do not want to use an Azure static IP address, you can remove the loadBalancerIP parameter from the first command.
The manifests we will deploy with Argo CD can be found in the following public git repository: https://github.com/gbaeke/argo-demo. The application is in three YAML files:
Two YAML files that create a certificate cluster issuer based on custom resource definitions (CRDs) from cert-manager
realtime.yaml: Redis deployment, Redis service (ClusterIP), realtime web app deployment (based on this), realtime web app service (ClusterIP), ingress resource for https://real.baeke.info (record automatically created by externaldns)
It’s best that you fork my repo and modify realtime.yaml’s ingress resource with your own DNS name.
Create the Argo app
Now you can create the Argo app based on my forked repo. I used the following command with my original repo:
The command above creates an app called realtime based on the specified repo. The app should use the manifests folder and apply (kubectl apply) all the manifests in that folder. The manifests are deployed to the cluster that Argo CD runs in. Note that you can run Argo CD in one cluster and deploy to totally different clusters.
The above command does not configure the repository to be synced automatically, although that is an option. To sync manually, use the following command:
argocd app sync realtime
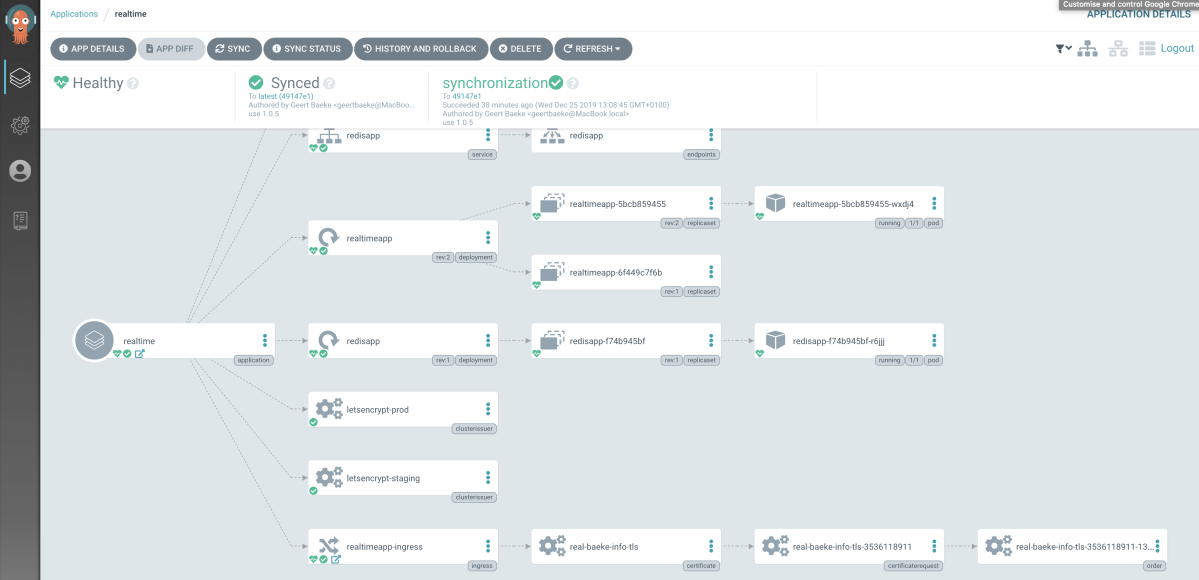
The application should now be synced and viewable in the UI:
Not Secure because we use Let’s Encrypt staging for this app
Set up auto-sync
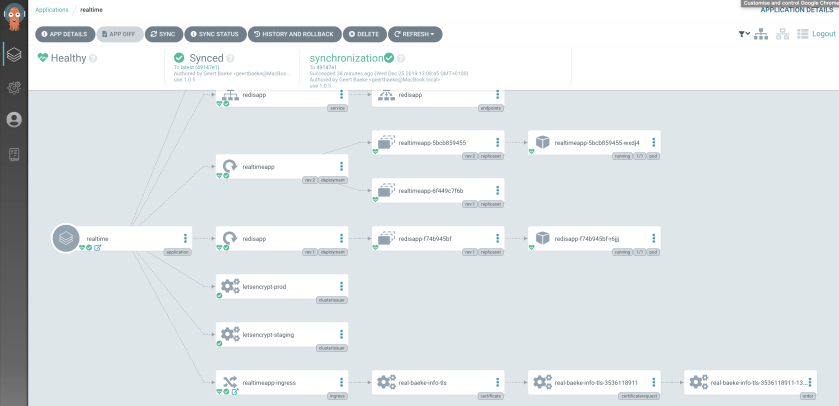
Let’s set up this app to automatically sync with the repo (default = every 3 minutes). This can be done from both the CLI and the UI. Let’s do it from the UI. Click on the app and then click App Details. You will find a Sync Policy in the app details where you can enable auto-sync
Setting up auto-sync from the UI
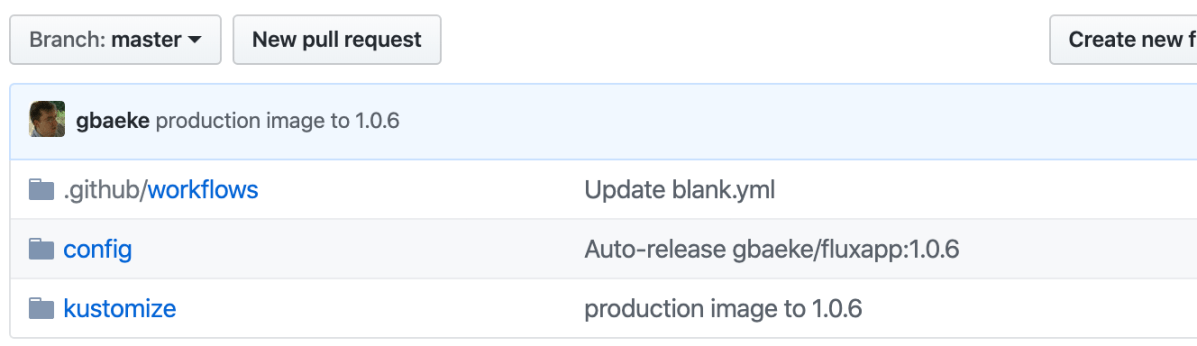
You can now make changes to the git repo like changing the image tag for gbaeke/fluxapp (yes, I used this image with the Flux posts as well 😊 ) to 1.0.6 and wait for the sync to happen. Or sync manually from the CLI or the UI.
Conclusion
This was a quick tour of Argo CD. There is much more you can do but the above should get you started quickly. I must say I quite like the solution and am eager to see what the collaboration of Flux CD, Argo CD and Amazon comes up with in the future.
Flux has a feature called manifest generation that works together with Kustomize. Instead of just picking YAML files from a git repo and applying them, customisation is performed with the kustomize build command. The resulting YAML then gets applied to your cluster.
If you don’t know how customisation works (without Flux), take a look at the article I wrote earlier. Or look at the core docs.
You need to be aware of a few things before you get started. In order for Flux to use this method, you need to turn on manifest generation. With the Flux Helm chart, just pass the following parameter:
--set manifestGeneration=true
In my case, I have plain YAML files without customisation in a config folder. I want the files that use customisation in a different folder, say kustomize, like so:
Two folders to pass as git.path
To pass these folders to the Helm chart, use the following parameter:
--set git.path="config\,kustomize"
The kustomize folder contains the following files:
base files with environments dev and prod
There is nothing special about the base folder here. It is as explained in my previous post. The dev and prod folders are similar so I will focus only on dev.
The dev folder contains a .flux.yaml file, which is required by Flux. In this simple example, it contains the following:
The file specifies the generator to use, in this case Kustomize. The kustomize executable is in the Flux image. I specify one patchFile which contains patches for several resources separated by —:
Above, you see the patches for the dev environment:
the workload should be automated by Flux, installing new images based on the semantic version filter ~1
the ingress should use host realdev.baeke.info with a different name for the secret as well (the secret will be created by cert-manager)
The prod folder contains a similar configuration. Perhaps naively, I thought that specifying the kustomize folder in git.path was sufficient for Flux to scan the folders and run customisation wherever a .flux.yaml file was found. Sadly, that is not the case. ☹️With just the kustomization folder specified, Flux find conflicts between base, dev and prod folders because they contain similar files. That is expected behaviour for regular YAML files but , in my opinion, should not happen in this case. There is a bit of a clunky way to make this work though. Just specify the following as git.path:
With the above parameter, Flux will find no conflicts and will happily apply the customisations.
As a side note, you should also specify the namespace in the patch file explicitly. It is not added automatically even though kustomization.yaml contains the namespace.
Let’s look at the cluster when Flux has applied the changes.
Namespaces for dev and prod created via Flux & Kustomize
And here is the deployed “production app”:
Who chose that ugly colour!
The way customisations are handled could be improved. It’s unwieldy to specify every “customisation” folder in the git.path parameter. Just give me a –git-kustomize-path parameter and scan the paths in that parameter for .flux.yaml files. On the other hand, maybe I am missing something here so remarks are welcome.
When you have to deploy an application to multiple environments like dev, test and production there are many solutions available to you. You can manually deploy the app (Nooooooo! 😉), use a CI/CD system like Azure DevOps and its release pipelines (with or without Helm) or maybe even a “GitOps” approach where deployments are driven by a tool such as Flux or Argo based on a git repository.
In the latter case, you probably want to use a configuration management tool like Kustomize for environment management. Instead of explaining what it does, let’s take a look at an example. Suppose I have an app that can be deployed with the following yaml files:
redis-deployment.yaml: simple deployment of Redis
redis-service.yaml: service to connect to Redis on port 6379 (Cluster IP)
realtime-deployment.yaml: application that uses the socket.io library to display real-time updates coming from a Redis channel
realtime-service.yaml: service to connect to the socket.io application on port 80 (Cluster IP)
realtime-ingress.yaml: ingress resource that defines the hostname and TLS certificate for the socket.io application (works with nginx ingress controller)
Let’s call this collection of files the base and put them all in a folder:
Base files for the application
Now I would like to modify these files just a bit, to install them in a dev namespace called realtime-dev. In the ingress definition I want to change the name of the host to realdev.baeke.info instead of real.baeke.info for production. We can use Kustomize to reach that goal.
In the base folder, we can add a kustomization.yaml file like so:
This lists all the resources we would like to deploy.
Now we can create a folder for our patches. The patches define the changes to the base. Create a folder called dev (next to base). We will add the following files (one file blurred because it’s not relevant to this post):
The namespace: realtime-dev ensures that our base resource definitions are updated with that namespace. In resources, we ensure that namespace gets created. The file namespace.yaml contains the following:
Note that we also use certmanager here to issue a certificate to use on the ingress. For dev environments, it is better to use the Let’s Encrypt staging issuer instead of the production issuer.
We are now ready to generate the manifests for the dev environment. From the parent folder of base and dev, run the following command:
kubectl kustomize dev
The above command generates the patched manifests like so:
Note that namespace realtime-dev is used everywhere and that the Ingress resource uses realdev.baeke.info. The original Ingress resource looked like below:
As you can see, Kustomize has updated the host in tls: and rules: and also modified the secret name (which will be created by certmanager).
You have probably seen that Kustomize is integrated with kubectl. It’s also available as a standalone executable.
To directly apply the patched manifests to your cluster, run kubectl apply -k dev. The result:
namespace/realtime-dev created
service/realtime created
service/redis created
deployment.apps/realtime created
deployment.apps/redis created
ingress.extensions/realtime-ingress created
In another post, we will look at using Kustomize with Flux. Stay tuned!
If you do any sort of development, you often have to deal with secrets. There are many ways to deal with secrets, one of them is retrieving the secrets from a secure system from your own code. When your application runs on Kubernetes and your code (or 3rd party code) cannot be configured to retrieve the secrets directly, you have several options. This post looks at one such solution: Azure Key Vault to Kubernetes from Sparebanken Vest, Norway.
In short, the solution connects to Azure Key Vault and does one of two things:
Create a regular Kubernetes secret with the controller
Inject the secrets in the pod with the Env Injector
In my scenario, I just wanted regular secrets to use in a KEDA project that processes IoT Hub messages. The following secrets were required:
Connection string to a storage account: AzureWebJobsStorage
Connection string to IoT Hub’s event hub: EventEndpoint
In the YAML that deploys the pods that are scaled by KEDA, the secrets are referenced as follows:
Because the YAML above is deployed with Flux from a git repo, we need to get the secrets from an external system. That external system in this case, is Azure Key Vault.
To make this work, we first need to install the controller that makes this happen. This is very easy to do with the Helm chart. By default, this Helm chart will work well on Azure Kubernetes Service as long as you give the AKS security principal read access to Key Vault:
Access policies in Key Vault (azure-cli-2019-… is the AKS service principal here)
Next, define the secrets in Key Vault:
Secrets in Key Vault
With the access policies in place and the secrets defined in Key Vault, the controller installed by the Helm chart can do its work with the following YAML:
The above YAML defines two objects of kind AzureKeyVaultSecret. In each object we specify the Key Vault secret to read (vault) and the Kubernetes secret to create (output). The above YAML results in two Kubernetes secrets:
Two regular secrets
When you look inside such a secret, you will see:
Inside the secret
To double check the secret, just do echo RW5K… | base64 -d to see the decoded secret and that it matches the secret stored in Key Vault. You can now reference the secret with ValueFrom as shown earlier in this post.
Conclusion
If you want to turn Azure Key Vault secrets into regular Kubernetes secrets for use in your manifests, give the solution from Sparebanken Vest a go. It is very easy to use. If you do not want regular Kubernetes secrets, opt for the Env Injector instead, which injects the environment variables directly in your pod.
I have always wanted to create a Kubernetes operator with the operator framework and tried to give that a go on my Windows 10 system. Note that the emphasis is on creating an operator, not necessarily writing a useful one 😁. All I am doing is using the boilerplate that is generated by the framework. If you have never even seen how this is done, then this post if for you. 👍
An operator is an application-specific controller. A controller is a piece of software that implements a control loop, watching the state of the Kubernetes cluster via the API. It makes changes to the state to drive it towards the desired state.
An operator uses Kubernetes to create and manage complex applications. Many operators can be found here: https://operatorhub.io/. The Cassandra operator for instance, has domain-specific knowledge embedded in it, that knows how to deploy and configure this database. That’s great because that means some of the burden is shifted from you to the operator.
Installation
I installed the Operator SDK CLI from the GitHub releases in WSL, Windows Subsystem for Linux. I am using WSL 1, not WSL 2 as I am not running a Windows Insiders release. The commands to run:
You should now be able to run operator-sdk in WSL 1.
Creating an operator
In WSL, you should have installed Go. I am using version 1.13.5. Although not required, I used my Go path on Windows to generate the operator and not the %GOPATH set in WSL. My working directory was:
/mnt/c/Users/geert/go/src/github.com/baeke.info
To create the operator, I ran the following commands (one line):
export GO111MODULE=on
operator-sdk new fun-operator --repo github.com/baeke.info/fun-operator
This creates a folder, fun-operator, under baeke.info and sets up the project:
Project structure in VS Code
Before continuing, cd into fun-operator and run go mod tidy. Now we can run the following command:
operator-sdk add api --api-version=fun.baeke.info/v1alpha1 --kind FunOp
This creates a new CRD (Custom Resource Definition) API called FunOp. The API version is fun.baeke.info/v1alpha1 which you choose yourself. With the above you can create CRDs like below that the operator acts upon:
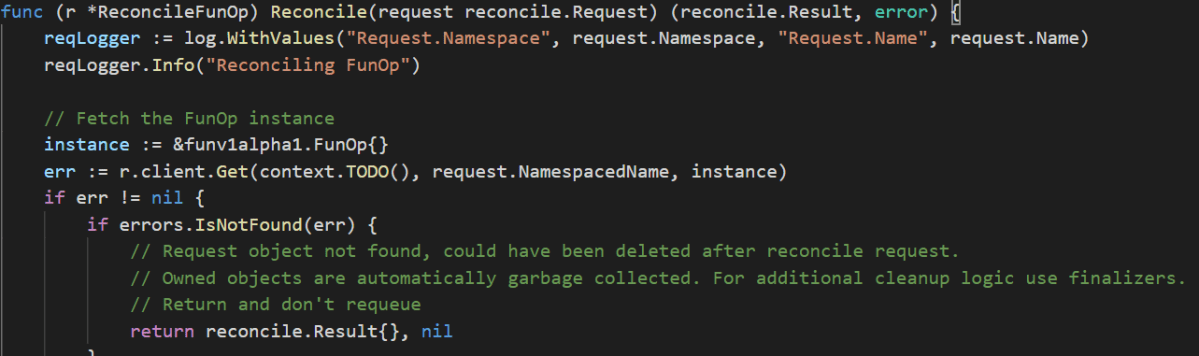
The above will generate a file, funop_controller.go, that contains some boilerplate code that creates a busybox pod. The Reconcile function is responsible for doing this work:
Reconcile function in the controller (incomplete)
As stated above, I will just use the boilerplate code and build the project:
operator-sdk build gbaeke/fun-operator
In WSL 1, you cannot run Docker so the above command will build the operator from the Go code but fail while building the container image. Can’t wait for WSL 2! The build creates the following artifact:
fun-operator in _output/bin
The supplied Dockerfile can be used to build the container images in Windows. In Windows, copy the Dockerfile from the build folder to the root of the operator project (in my case C:\Users\geert\go\src\github.com\baeke.info\fun-operator) and run docker build and push:
The project folder structure contains a bunch of yaml in the deploy folder:
Great! Some YAML to deploy
The service account, role and role binding make sure your code can create (or delete/update) resources in the cluster. The operator.yaml actually deploys the operator on your cluster. You just need to update the container spec with the name of your image (here gbaeke/fun-operator).
Before you deploy the operator, make sure you deploy the CRD manifest (here fun.baeke.info_funops_crd.yaml).
As always, just use kubectl apply-f with the above YAML files.
Testing the operator
With the operator deployed, create a resource based on the CRD. For instance:
From the moment you create this resource with kubectl apply, a pod will be created by the operator.
pod created upon submitting the custom resource
When you delete example-funop, the pod will be removed by the operator.
That’s it! We created a Kubernetes operator with the boilerplate code supplied by the operator-sdk cli. Another time, maybe we’ll create an operator that actually does something useful! 😉
In a previous post, we built a pipeline to deploy AKS using Azure DevOps. Because it can take while to deploy, it can be handy to start the deployment at any time without having to logon to Azure DevOps. There are many ways to achieve this, but one of the easiest ways is Power Automate.
Microsoft have made it easy to create such a flow because they support Azure DevOps out of the box. The flow looks like this:
Flow to trigger an Azure DevOps build
The flow uses a manual trigger which allows you to start the flow from the iOS app using a button:
In the previous post, I deployed AKS, Nginx, External DNS, Helm Operator and Flux with a YAML pipeline in Azure DevOps. Flux got linked to a git repo that contains a bunch of yaml files that deploy applications to the cluster but also configures Azure Monitor. Flux essentially synchronizes your cluster with the configuration in the git repository.
In production, it is not a good idea to simply drop in some yaml and let Flux do its job. Similar to traditional software development, you want to run some tests before you deploy. For Kubernetes yaml files, kubeval is a tool that can run those tests.
I refactored the git repository to have all yaml files in a config folder. To check all yaml files in that folder, the following command can be used:
With -d you specify the folder (and all its subfolders) where kubeval should look for yaml files. The –strict option checks for properties in your yaml file that are not part of the official schema. If you know you need those, you can leave out –strict. With –ignore-missing-schemas, kubeval will ignore yaml files that use custom schemas not in the Kubernetes OpenAPI spec. In my case for instance, the yaml file that deploys a Helm chart (of kind HelmRelease) is such a file. You can also instruct kubeval to ignore specific “kinds” with –skip-kinds. Here’s the result of running the command:
Result of kubeval
Using a GitHub action
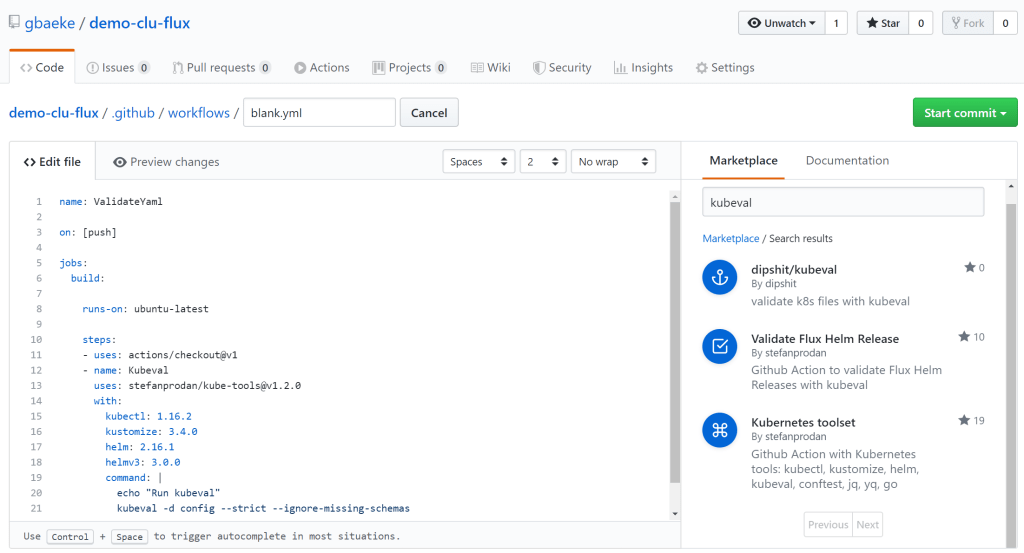
To automate the testing of your files, you can use any CI system like Azure DevOps, CircleCI, etc… In my case, I decided to use a GitHub action. See the getting started for more information about the basics of GitHub Actions. The action I created is easy (hey, it’s my first time using Actions 😊):
GitHub Action to validate YAML with kubeval
An action is defined in yaml 😉 and consists of jobs and steps, similarly to Azure DevOps and the likes. The action is run on Ubuntu (hosted by GitHub) and uses an action from the marketplace called Kubernetes toolset. You can easily search for actions in the editor:
Actions in the marketplace
The first step uses an action to checkout your code. Indeed, you need to do that explicitly. Then we use the Kubernetes Toolset to give us access to all kinds of Kubernetes related tools such as kubectl and kubeval. The toolset is just a container which you’ll see getting pulled at runtime. After that, we simple run kubeval in the container which will have mounted the working directory which also contains your checked out code.
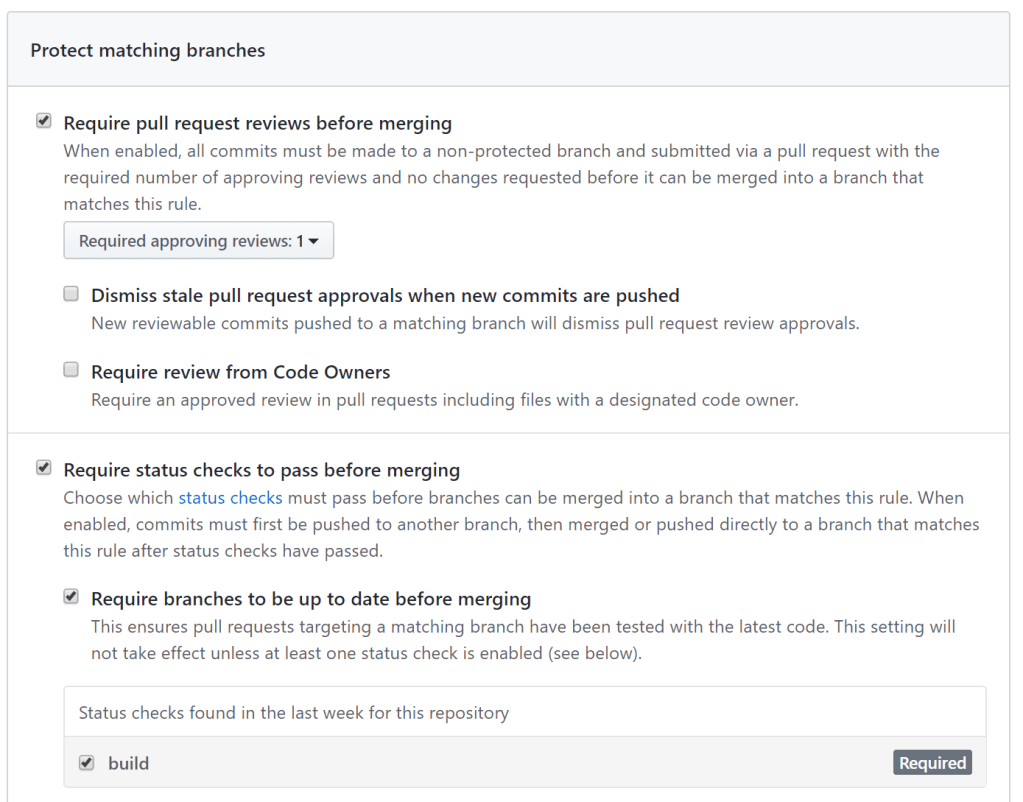
In the repository settings, I added a branch protection rule that requires a pull request review before merging plus a status check that must pass (the action):
Branch protection rules
The pull request below shows a check that did not pass, a violation of the –strict setting in error.yaml:
Failed status check before merging
There are many other tools and techniques that can be used to validate your configuration but this should get you started with some simple checks on yaml files.
As a last note, know that kubeval generates schemas from the Kubernetes OpenAPI specs. You can set the version of Kubernetes with the -v option.
A while ago, I blogged about an Azure YAML pipeline to deploy AKS together with Traefik. As a variation on that theme, this post talks about deploying AKS together with Nginx, External DNS, a Helm Operator and Flux CD. I blogged about Flux before if you want to know what it does.
Let’s break the pipeline down a little. In what follows, replace AzureMPN with a reference to your own subscription. The first two tasks, AKS deployment and IP address deployment are ARM templates that deploy these resources in Azure. Nothing too special there. Note that the AKS cluster is one with default networking, no Azure AD integration and without VMSS (so no multiple node pools either).
Note: I modified the pipeline to deploy a VMSS-based cluster with a standard load balancer, which is recommended instead of a cluster based on an availability set with a basic load balancer.
The third task takes the output of the IP address deployment and parses out the IP address using jq (last echo statement on one line):
For External DNS to work, I found I had to set controller.publishService.enabled=true. As you can see, the Nginx service is configured to use the IP we created earlier. Azure will create a load balancer with a front end IP configuration that uses this address. This all happens automatically.
Note: controller.metrics.enabled enables a Prometheus scraping endpoint; that is not discussed further in this blog
External DNS
External DNS can automatically add DNS records for ingresses and services you add to Kubernetes. For instance, if I create an ingress for test.baeke.info, External DNS can create this record in the baeke.info zone and use the IP address of the Ingress Controller (nginx here). Installation is pretty straightforward but you need to provide credentials to your DNS provider. In my case, I use CloudFlare. Many others are available. Here is the task:
On CloudFlare, I created a token that has the required access rights to my zone (read, edit). I provide that token to the chart via the CFAPIToken variable defined as a secret on the pipeline. The valueFile looks like this:
In the beginning, it’s best to set the logLevel to debug in case things go wrong. With interval 1m, External DNS checks for ingresses and services every minute and syncs with your DNS zone. Note that External DNS only touches the records it created. It does so by creating TXT records that provide a record that External DNS is indeed the owner.
With External DNS in place, you just need to create an ingress like below to have the A record real.baeke.info created:
This installs the latest version of the operator at the time of this writing (image.repository and image.tag) and also sets Helm to v3. With this installed, you can install a Helm chart by submitting files like below:
You can create files that use kind HelmRelease (HR) because we installed the Helm Operator CRD before. To check installed Helm releases in a namespace, you can run kubectl get hr.
The Helm operator is useful if you want to install Helm charts from a git repository with the help of Flux CD.
The gitURL variable should be set to a git repo that contains your cluster configuration. For instance: gbaeke/demo-clu-flux. Flux will check the repo for changes every minute. Note that we are using a public repo here. Private repos and systems other than GitHub are supported.
Use fluxctl identity to obtain the public key from the key pair created by Flux (when you do not use your own)
Set the public key as a deploy key on the git repo
GitHub deploy key
By connecting the https://github.com/gbaeke/demo-clu-flux repo to Flux CD (as done here), the following is done based on the content of the repo (the complete repo is scanned:
Install InfluxDB Helm chart
Add a simple app that uses a Go socket.io implementation to provide realtime updates based on Redis channel content; this app is published via nginx and real.baeke.info is created in DNS (by External DNS)
Adds a ConfigMap that is used to configure Azure Monitor to enable Prometheus endpoint scraping (to show this can be used for any object you need to add to Kubernetes)
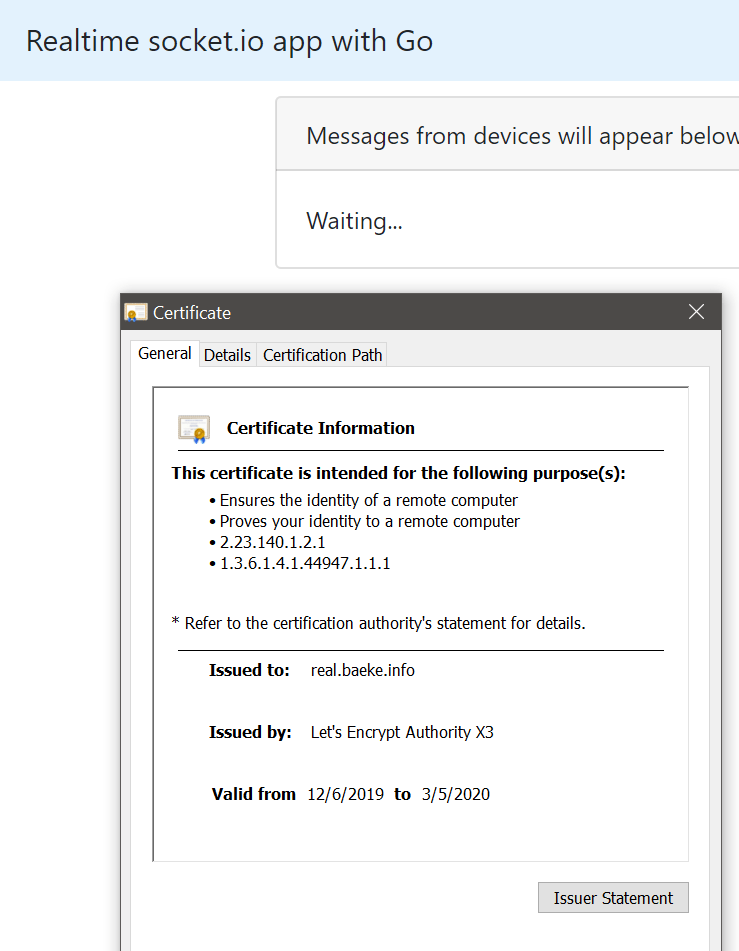
Note that the ingress of the Go app has an annotation (in realtime.yaml, in the git repo) to issue a certificate via cert-manager. If you want to make that work, add an extra task to the pipeline that installs cert-manager:
You will also need to create another namespace, cert-manager, just like we created the fluxcd namespace.
In order to make the above work, you will need Issuers or ClusterIssuers. The repo used by Flux CD contains two ClusterIssuers, one for Let’s Encrypt staging and one for production. The ingress resource uses the production issuer due to the following annotation:
Here’s a quick overview of the steps you need to take to put Front Door in front of an Azure Web App. In this case, the web app runs a WordPress site.
Step 1: DNS
Suppose you deployed the Web App and its name is gebawptest.azurewebsites.net and you want to reach the site via wp.baeke.info. Traffic will flow like this:
user types wp.baeke.info ---CNAME to xyz.azurefd.net--> Front Door --- connects to gebawptest.azurewebsites.net using wp.baeke.info host header
It’s clear that later, in Front Door, you will have to specify the host header (wp.baeke.info in this case). More on that later…
If you have worked with Azure Web App before, you probably know you need to configure the host header sent by the browser as a custom domain on the web app. Something like this:
Custom domain in Azure Web App (no https configured – hence the red warning)
In this case, we do not want to resolve wp.baeke.info to the web app but to Front Door. To make the custom domain assignment work (because the web app will verify the custom name), add the following TXT record to DNS:
TXT awverify.wp gebawptest.azurewebsites.net
For example in CloudFlare:
awverify txt record in CloudFlare DNS
With the above TXT record, I could easily add wp.baeke.info as a custom domain to the gebawptest.azurewebsites.net web app.
Note: wp.baeke.info is a CNAME to your Front Door domain (see below)
Step 2: Front Door
My Front Door designer looks like this:
Front Door designer
When you create a Front Door, you need to give it a name. In my case that is gebafd.azurefd.net. With wp.baeke.info as a CNAME for gebafd.azurefd.net, you can easily add wp.baeke.info as an additional Frontend host.
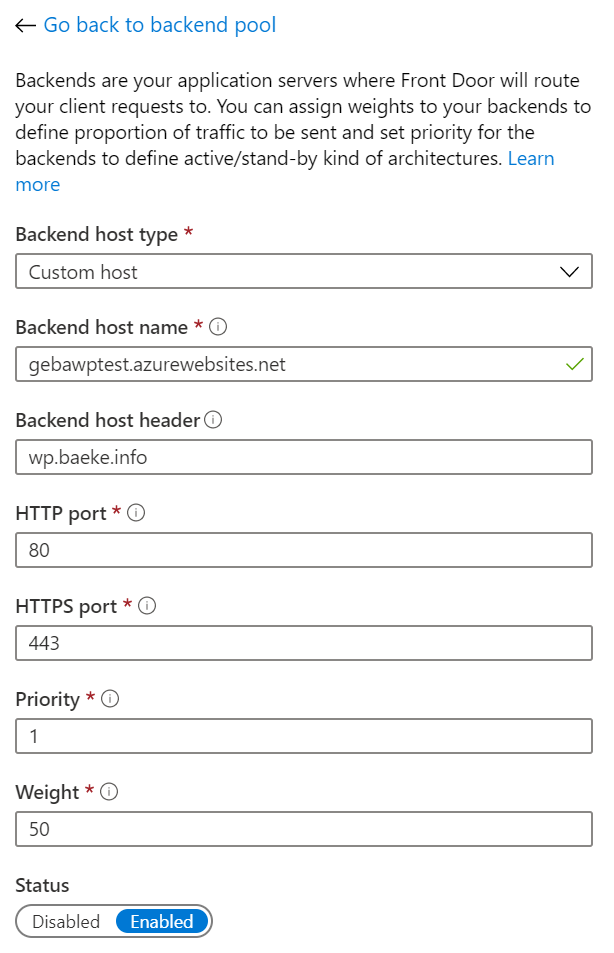
The backend pool is the Azure Web App. It’s configured as follows:
Front Door backend host (only one in the pool); could also have used the Azure App Service backend type
You should connect to the web app using its original name but send wp.baeke.info as the host header. This allows Front Door to connect to the web app correctly.
The last part of the Front Door config is a simple rule that connects the frontend wp.baeke.info to the backend pool using HTTP only.
Step 3: WordPress config
With the default Azure WordPress templates, you do not need to modify anything because wp-config.php contains the following settings: