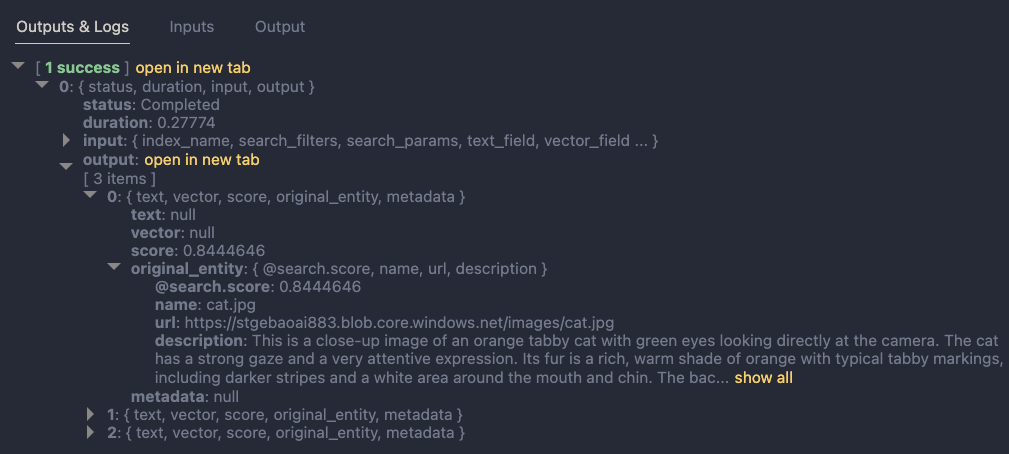
It’s a common request we hear from clients: “We want a chatbot that can interact with our data in SharePoint!” The idea is compelling – instead of relying on traditional search methods or sifting through hundreds of pages and documents, users could simply ask the bot a question and receive an instant, accurate answer. It promises to be a much more efficient and user-friendly experience.
The appeal is clear:
- Improved user experience
- Time savings
- Increased productivity
But how easy is it to implement a chatbot for SharePoint and what are some of the challenges? Let’s try and find out.
The easy way: Copilot Studio
I have talked about Copilot Studio in previous blog posts. One of the features of Copilot Studio is generative answers. With generative answers, your copilot can find and present information for different sources like web sites or SharePoint data. The high level steps to work with SharePoint data are below:
- Configure your copilot to use Microsoft Entra ID authentication
- In the Create generative answers node, in the Data sources field, add the SharePoint URLs you want to work with
From a high level, this is all you need to start asking questions. One advantage of using this feature is that the SharePoint data is accessed on behalf of the user. When generative answers searches for SharePoint data, it only returns information that the user has access to.
It is important to note that the search relies on a call to the Graph API search endpoint (https://graph.microsoft.com/v1.0/search/query) and that only the top three results that come back from this call are used. Generative answers only works with files up to 3MB in size. It is possible that the search returns documents that are larger than 3MB. They would not be processed. If all results are above 3MB, generative answers will return an empty response.
In addition, the user’s question is rewritten to only send the main keywords to the search. The type of search is a keyword search. It is not a similarity search based on vectors.
Note: the type of search will change when Microsoft enables Semantic Index for Copilot for your tenant. Other limitations, like the 3MB size limit, will be removed as well.
Pros:
- easy to configure (UI)
- uses only documents the user has access to (Entra ID integration)
- no need to create a pipeline to process SharePoint data; simply point at SharePoint URLs 🔥
- an LLM is used “under the hood”; there is no need to setup an Azure OpenAI instance
Cons:
- uses keyword search which can result in less relevant results
- does not use vector search and/or semantic reranking (e.g., like in Azure AI Search)
- number of search results that can provide context is not configurable (maximum 3)
- documents are not chunked; search can not retrieve relevant pieces of text from a document
- maximum size is 3MB; if the document is highly relevant to answer the user’s query, it might be dropped because of its size
Although your mileage may vary, the limitations make it hard to build a chat bot that provides relevant and qualitative answers. What can we do to fix that?
Copilot Studio with Azure OpenAI on your data
Copilot Studio has integration with Azure OpenAI on your data. Azure OpenAI on your data makes it easy to create an Azure AI Search index based on your documents. Such an index creates chunks of larger documents and uses vectors to match a user’s query to similar chunks. Such queries usually result in more relevant pieces of text from multiple documents. In addition to vector search, you can combine vector search with keyword search and optionally rerank the search results semantically. In most cases, you want these advanced search options because relevant context is key for the LLM to work with!
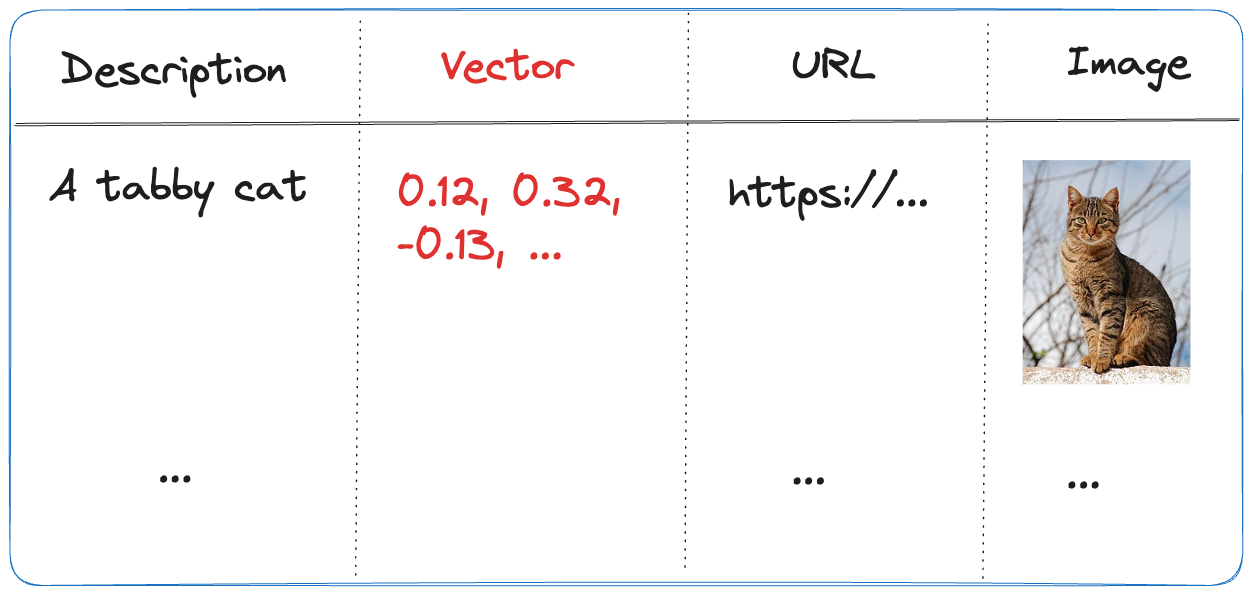
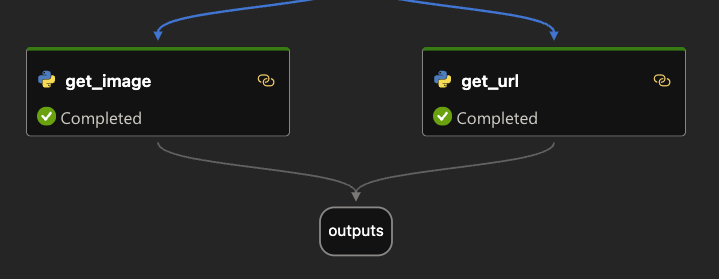
The diagram below shows the big picture:

The diagram above shows documents in a storage account (not SharePoint, we will get to that). With Azure OpenAI on your data, you simply point to the storage account, allowing Azure AI Search to build an index that contains one or more document chunks per document. The index contains the text in the chunk and a vector of that text. Via the Azure OpenAI APIs, chat applications (including Copilot Studio) can send user questions to the service together with information about the index that contains relevant content. Behind the scenes, the API searches for similar chunks and uses them in the prompt to answer the user’s question. You can configure the number of chunks that should be put in the prompt. The number is only limited by the OpenAI model’s context limit (8k, 16k, 32k or 128k tokens).
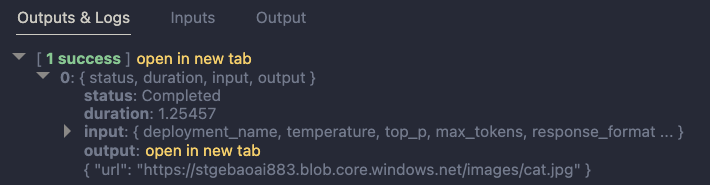
You do not need to write code to create this index. Azure OpenAI on your data provides a wizard to create the index. The image below shows the wizard in Azure AI Studio (https://ai.azure.com):

Above, instead of pointing to a storage account, I selected the Upload files/folder feature. This allows you to upload files to a storage account first, and then create the index from that storage account.
Azure OpenAI on your data is great, but there is this one tiny issue: there is no easy way to point it to your SharePoint data!
It would be fantastic if SharePoint was a supported datasource. However, it is important to realise that SharePoint is not a simple datasource:
- What credentials are used to create the index?
- How do you ensure that queries use only the data the user has access to?
- How do you keep the SharePoint data in sync with the Azure AI Search index? And not just the data, the ACLs (access control lists) too.
- What SharePoint data do you support? Just documents? List items? Web pages?
The question now becomes: “How do you get SharePoint data into AI Search to improve search results?” Let’s find out.
Creating an AI Search index with SharePoint data
Azure AI Search offers support for SharePoint as a data source. However, it’s important to note that this feature is currently in preview and has been in that state for an extended period of time. Additionally, there are several limitations associated with this functionality:
- SharePoint .ASPX site content is not supported.
- Permissions are not automatically ingested into the index. To enable security trimming, you will need to add permission-related information to the index manually, which is a non-trivial task.
In the official documentation, Microsoft clearly states that if you require SharePoint content indexing in a production environment, you should consider creating a custom connector that utilizes SharePoint webhooks in conjunction with the Microsoft Graph API to export data to an Azure Blob container. Subsequently, you can leverage the Azure Blob indexer to index the exported content. This approach essentially means that you are responsible for developing and maintaining your own custom solution.
Note: we do not follow the approach with webhooks because of its limitations
What to do?
When developing chat applications that leverage retrieval-augmented generation (RAG) with SharePoint data, we typically use a Logic App or custom job to process the SharePoint data in bulk. This Logic App or job ingests various types of content, including documents and site pages.
To maintain data integrity and ensure that the system remains up-to-date, we also utilize a separate Logic App or job that monitors for changes within the SharePoint environment and updates the index accordingly.
However, implementing this solution in a production environment is not a trivial task, as there are numerous factors to consider:
- Logic Apps have limitations when it comes to processing large volumes of data. Custom code can be used as a workaround.
- Determining the appropriate account credentials for retrieving the data securely.
- Identifying the types of changes to monitor: file modifications, additions, deletions, metadata updates, access control list (ACL) changes, and more.
- Ensuring that the index is updated correctly based on the detected changes.
- Implementing a mechanism to completely rebuild the index when the data chunking strategy changes, typically involving the creation of a new index and updating the bot to utilize the new index. Index aliases can be helpful in this regard.
In summary, building a custom solution to index SharePoint data for chat applications with RAG capabilities is a complex undertaking that requires careful consideration of various technical and operational aspects.
Security trimming
Azure AI Search does not provide document-level permissions. There is also no concept of user authentication. This means that you have to add security information to an Azure AI Search index yourself and, in code, ensure that AI Search only returns results that the logged on user has access to.
Full details are here with the gist of it below:
- add a security field of type collection of strings to your index; the field should allow filtering
- in that field, store group Ids (e.g., Entra ID group oid’s) in the array
- while creating the index, retrieve the group Ids that have at least read access to the document you are indexing; add each group Id to the security field
When you query the index, retrieve the logged on user’s list of groups. In your query, use a filter like the one below:
{
"filter":"group_ids/any(g:search.in(g, 'group_id1, group_id2'))"
}Above, group_ids is the security field and group_id1 etc… are the groups the user belongs to.
For more detailed steps and example C# code, see https://learn.microsoft.com/en-us/azure/search/search-security-trimming-for-azure-search-with-aad.
If you want changes in ACLs in SharePoint to be reflected in your index as quickly as possible, you need a process to update the security field in your index that is triggered by ACL changes.
Conclusion
Crafting a chat bot that seamlessly works with SharePoint data to deliver precise answers is no simple feat. Should you manage to obtain satisfactory outcomes leveraging generative responses within Copilot Studio, it’s advisable to proceed with that route. Even if you do not use Copilot Studio, you can use Graph API search within custom code.
If you want more accurate search results and switch to Azure AI Search, be mindful that establishing and maintaining the Azure AI Search index, encompassing both SharePoint data and access control lists, can be quite involved.
It seems Microsoft is relying on the upcoming Semantic Index capability to tackle these hurdles, potentially in combination with Copilot for Microsoft 365. When Semantic Index ultimately becomes available, executing a search through the Graph API could potentially fulfill your requirements.