A while ago, OpenAI introduced GPTs. A GPT is a custom version of ChatGPT that combine instructions, extra knowledge, and any combination of skills.
In this tutorial, we are going to create a custom GPT that can answer questions about articles on this blog. In order to achieve that, we will do the following:
- create an Azure AI Search index
- populate the index with content of the last 50 blog posts (via its RSS feed)
- create a custom API with FastAPI (Python) that uses the Azure OpenAI “add your data” APIs to provide relevant content to the user’s query
- add the custom API as an action to the custom GPT
The image below shows the properties of the GPT. You need to be a ChatGPT Plus subscriber to create a GPT.

To implement a custom action for the GPT, you need an API with an OpenAPI spec. When you use FastAPI, an OpenAPI JSON document can easily be downloaded and provided to the GPT. You will need to modify the JSON document with a servers section to specify the URL the GPT has to use.
In what follows, we will look at all of the different pieces that make this work. Beware: long post! 😀
Azure AI Search Index
Azure AI Search is a search service you create in Azure. Although there is a free tier, I used the basic tier. The basic tiers allows you to use its semantic reranker to optimise search results.
To create the index and populate it with content, I used the following notebook: https://github.com/gbaeke/custom-gpt/blob/main/blog-index/website-index.ipynb.
The result is an index like below:

The index contains 292 documents although I only retrieve the last 50 blog posts. This is the result of chunking each post into smaller pieces of about 500 tokens with 100 tokens of overlap for each chunk. We use smaller chunks because we do not want to send entire blog posts as content to the large language model (LLM).
Note that the index supports similarity searches using vectors. The contentVector field contains the OpenAI embedding of the text in the content field.
Although vectors are available, we do not have to use vector search. Azure AI search supports simple keyword search as well. Together with the semantic ranker, it can provide more relevant results than keyword search on its own.
Note: in general, vector search will provide better results, especially when combined with keyword search and the semantic ranker
Use the index with Azure OpenAI “add your data”
I have written about the Azure OpenAI “add your data” features before. It provides a wizard experience to add an Azure AI Search index to the Azure OpenAI playground and directly test your index with the model of your choice.
From you Azure OpenAI instance, first open Azure OpenAI Studio:
Note: you still need to complete a form to get access to Azure OpenAI. Currently, it can take around a day before you are allowed to create Azure OpenAI instances in your subscription.
In Azure OpenAI Studio, click Bring your own data from the Home screen:

Select the Azure AI Search index and click Next.
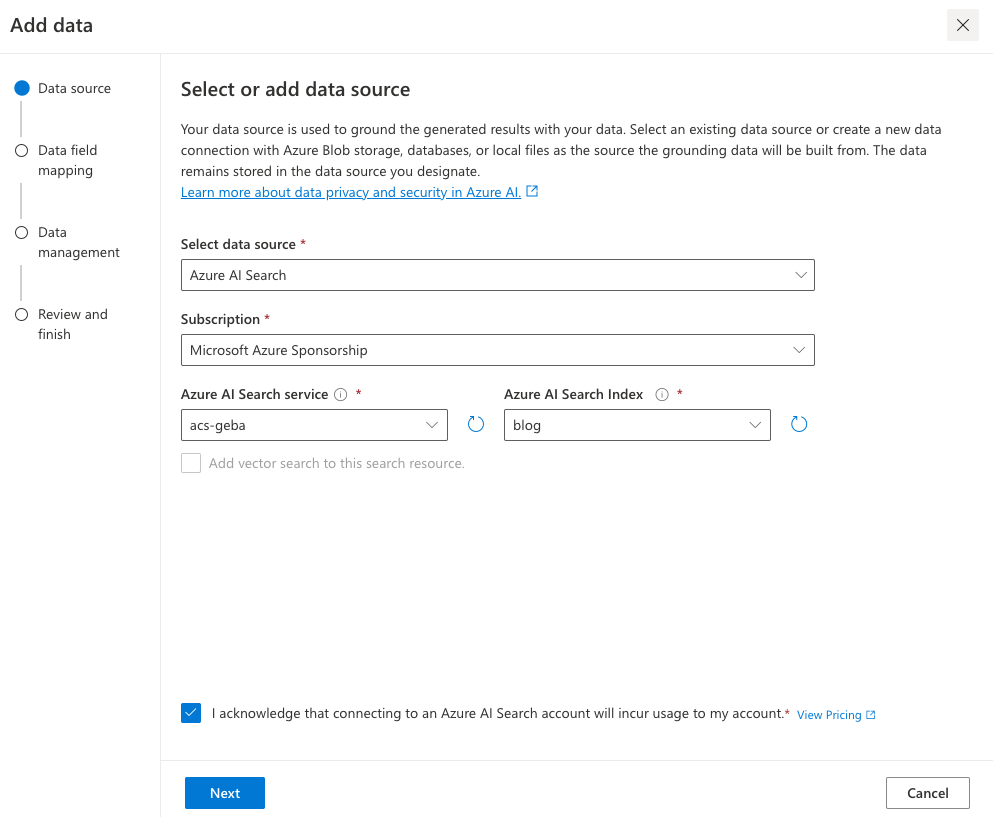
Note: I created the index using the generally available API that supports vector search. The Add your data wizard, at the time of writing, was not updated yet to support these new indexes. That is the reason why vector search cannot be enabled. We will use keyword + semantic search instead. I expect this functionality to be available soon (November/December 2023).
Next, provide field mappings:

These mappings are required because the Add your data feature excepts these standard fields. You should have at least a content field to search. Above, I do not have a file name field because I have indexed blog posts. It’s ok to leave that field blank.
After clicking Next, we get to data management:

Here, we specify the type of search. Semantic means keyword + semantic. In the dropdown list, you can also select keyword search on its own. However, that might give you less relevant results.
Note: for Semantic to work, you need to turn on the Semantic ranker on the Azure AI Search resource. Additionally, you need to create a semantic profile on the index.
Now you can click Next, followed by Save and close. The Azure OpenAI Chat Playground appears with the index added:
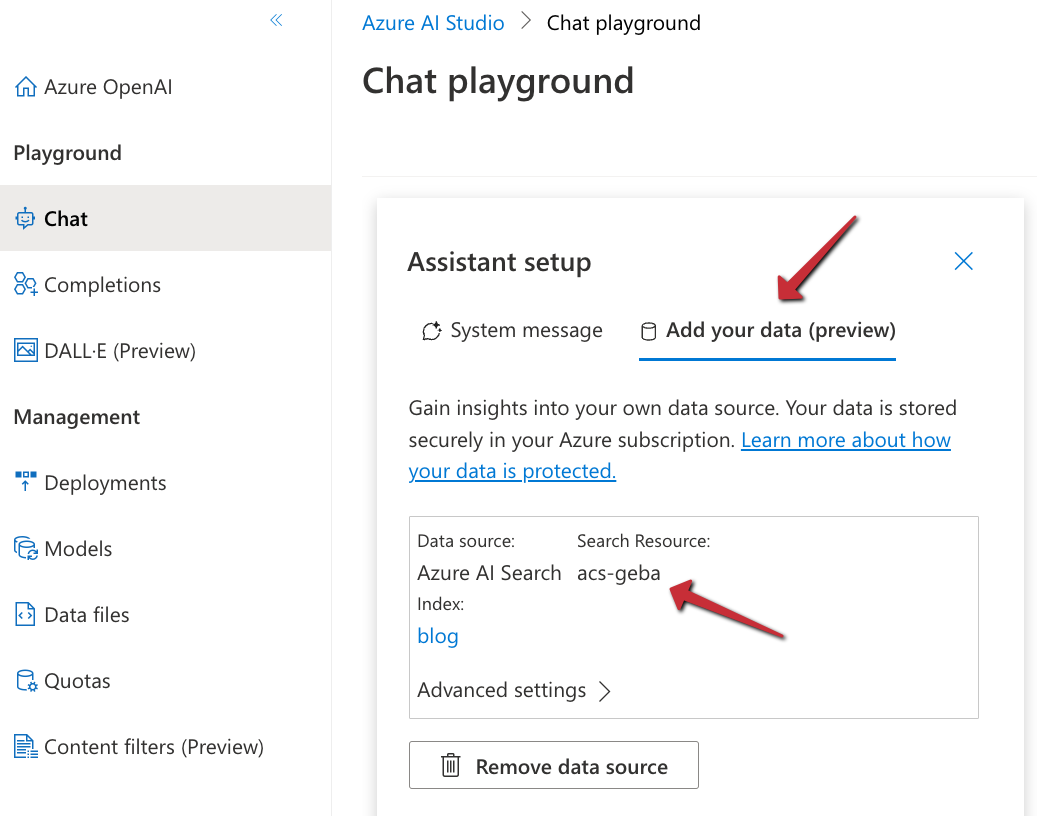
You can now start chatting with your data. Select a chat model like gpt-4 or gpt-35-turbo. In Azure OpenAI, you have to deploy these models first and give the deployment a name.

Above, I asked about the OpenAI Assistants API, which is one of the posts on my blog. In the background, the playground performs a search on the Azure AI Search index and provides the results as context to the model. The gpt-35-turbo model answers the user’s question, based on the context coming from the index.
When you are happy with the result, you can export this experience to an Azure Web App of CoPilot Studio (Power Virtual Agents):

In our case, we want to use this configuration from code and provide an API we can add to the custom GPT.
⚠️ It’s import to realise that, with this approach, we will send the final answer, generated by an Azure OpenAI model, to the custom GPT. An alternate approach would be to hand the results of the Azure AI Search query to the custom GPT and let it formulate the answer on its own. That would be faster and less costly. If you also provide the blog post’s URL, ChatGPT can refer to it. However, the focus here is on using any API with a custom GPT so let’s continue with the API that uses the “add your data” APIs.
If you want to hand over Azure AI search results directly to ChatGPT, check out the code in the azure-ai-search folder in the Github repo.
Creating the API
To create an API that uses the index with the model, as configured in the playground, we can use some code. In fact, the playground provides sample code to work with:

‼️ Sadly, this code will not work due to changes to the openai Python package. However, the principle is still the same:
- call the chat completion extension API which is specific to Azure; in the code you will see this is as a Python f-string:
f"{openai.api_base}/openai/deployments/{deployment_id}/extensions/chat/completions?api-version={openai.api_version}" - the JSON payload for this API needs to include the Azure AI Search configuration in a dataSources array.
The extension API will query Azure AI Search for you and create the prompt for the chat completion with context from the search result.
To create a FastAPI API that does this for the custom GPT, I decided to not use the openai package and simply use the REST API. Here is the code:
from fastapi import FastAPI, HTTPException, Depends, Header
from pydantic import BaseModel
import httpx, os
import dotenv
import re
# Load environment variables
dotenv.load_dotenv()
# Initialize FastAPI app
app = FastAPI()
# Constants (replace with your actual values)
api_base = "https://oa-geba-france.openai.azure.com/"
api_key = os.getenv("OPENAI_API_KEY")
deployment_id = "gpt-35-turbo"
search_endpoint = "https://acs-geba.search.windows.net"
search_key = os.getenv("SEARCH_KEY")
search_index = "blog"
api_version = "2023-08-01-preview"
# Pydantic model for request body
class RequestBody(BaseModel):
query: str
# Define the API key dependency
def get_api_key(api_key: str = Header(None)):
if api_key is None or api_key != os.getenv("API_KEY"):
raise HTTPException(status_code=401, detail="Invalid API Key")
return api_key
# Endpoint to generate response
@app.post("/generate_response", dependencies=[Depends(get_api_key)])
async def generate_response(request_body: RequestBody):
url = f"{api_base}openai/deployments/{deployment_id}/extensions/chat/completions?api-version={api_version}"
headers = {
"Content-Type": "application/json",
"api-key": api_key
}
data = {
"dataSources": [
{
"type": "AzureCognitiveSearch",
"parameters": {
"endpoint": search_endpoint,
"key": search_key,
"indexName": search_index
}
}
],
"messages": [
{
"role": "system",
"content": "You are a helpful assistant"
},
{
"role": "user",
"content": request_body.query
}
]
}
async with httpx.AsyncClient() as client:
response = await client.post(url, json=data, headers=headers, timeout=60)
if response.status_code != 200:
raise HTTPException(status_code=response.status_code, detail=response.text)
response_json = response.json()
# get the assistant response
assistant_content = response_json['choices'][0]['message']['content']
assistant_content = re.sub(r'\[doc.\]', '', assistant_content)
# return assistant_content as json
return {
"response": assistant_content
}
# Run the server
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000, timeout_keep_alive=60)
This API has one endpoint: /generate_response that takes { "query": "your query" }as input and returns { "response": assistant_content }as output. Note that the original response from the model contains references like [doc1], [doc2], etc… The regex in the code removes those references. I don not particularly like how the references are handled by the API so I decided to not include them and simplify the response.
The endpoint expects an api-key header. It it is not present, it returns an error.
The endpoint does a call to the Azure OpenAI chat completion extension API which looks very similar to a regular OpenAI chat completion. The request does however, contain a dataSources field with the Azure AI Search information.
The environment variables like the OPENAI_API_KEY and the SEARCH_KEY are retrieved from a .env file.
Note: to stress this again, this API returns the answer to the query as generated by the chosen Azure OpenAI model. This allows it to be used in any application, not just a custom GPT. For a custom GPT in ChatGPT, an alternate approach would be to hand over the search results from Azure AI search directly, allowing the model in the custom GPT to generate the response. It would be faster and avoid Azure OpenAI costs. We are effectively using the custom GPT as a UI and as a way to maintain history between action calls. 😀
If you want to see the code in GitHub, check this URL: https://github.com/gbaeke/custom-gpt.
Running the API in Azure Container Apps
To run the API in the cloud, I decided to use Azure Container Apps. That means we need a Dockerfile to build the container image locally or in the cloud:
# Use an official Python runtime as a parent image
FROM python:3.9-slim-buster
# Set the working directory in the container to /app
WORKDIR /app
# Add the current directory contents into the container at /app
ADD . /app
# Install any needed packages specified in requirements.txt
RUN pip install --no-cache-dir -r requirements.txt
# Run app.py when the container launches
CMD ["python3", "app.py"]
We also need a requirements.txt file:
fastapi==0.104.1
pydantic==2.5.2
pydantic_core==2.14.5
httpx==0.25.2
python-dotenv==1.0.0
uvicorn==0.24.0.post1
I use the following shell script to build and run the container locally. The script can also push the container to Azure Container Apps.
#!/bin/bash
# Load environment variables from .env file
export $(grep -v '^#' .env | xargs)
# Check the command line argument
if [ "$1" == "build" ]; then
# Build the Docker image
docker build -t myblog .
elif [ "$1" == "run" ]; then
# Run the Docker container, mapping port 8000 to 8000 and setting environment variables
docker run -p 8000:8000 -e OPENAI_API_KEY=$OPENAI_API_KEY -e SEARCH_KEY=$SEARCH_KEY -e API_KEY=$API_KEY myblog
elif [ "$1" == "up" ]; then
az containerapp up -n myblog --ingress external --target-port 8000 \
--env-vars OPENAI_API_KEY=$OPENAI_API_KEY SEARCH_KEY=$SEARCH_KEY API_KEY=$API_KEY \
--source .
else
echo "Usage: $0 {build|run|up}"
fi
The shell script extracts the environment variables defined in .env and sets them in the session. Next, we check the first parameter given to the script (Docker is required on your machine for build and run):
- build: build the Docker image
- run: run the Docker image locally on port 8000 and specify the environment variables to authenticate to Azure OpenAI and Azure AI Search
- up: build the Docker image in the cloud and run it in Container Apps; if you do not have a Container Apps Environment or Azure Container Registry, they will be created for you. In the end, you will get an https endpoint to your API in the cloud.
Note: you should not put secrets in environment variables in Azure Container Apps directly; use Container Apps secrets or Key Vault instead; the above is just quick and easy to simplify the deployment
To test the API locally, use the REST Client extension in VS Code with an .http file:
POST http://localhost:8000/generate_response HTTP/1.1
Host: localhost:8000
Content-Type: application/json
api-key: API_KEY_FROM_DOTENV
{
"query": "what is the openai assistants api?"
}
###
POST https://AZURE_CONTAINER_APPS_ENDPOINT/generate_response HTTP/1.1
Host: AZURE_CONTAINER_APPS_ENDPOINT
Content-Type: application/json
api-key: API_KEY_FROM_DOTENV
{
"query": "Can I use Redis as a vector db?"
}
When you get something like below, you are good to go. Note again that we return a final answer and not the relevant chunks from Azure AI search.

Getting the OpenAPI spec and adding it to the GPT
With your API running, you can go to its URL, like this one if the API runs locally: http://localhost:8000/openapi.json. The result is a JSON document you can copy to your GPT. I recommend to copy the JSON to VS Code and format it before you paste it in the GPT.
In the GPT, modify the OpenAPI spec with a servers section that includes your Azure Container Apps ingress URL:

If you want to give the ability to the user to trust the action to be called without approval (after a first call), also add the following:
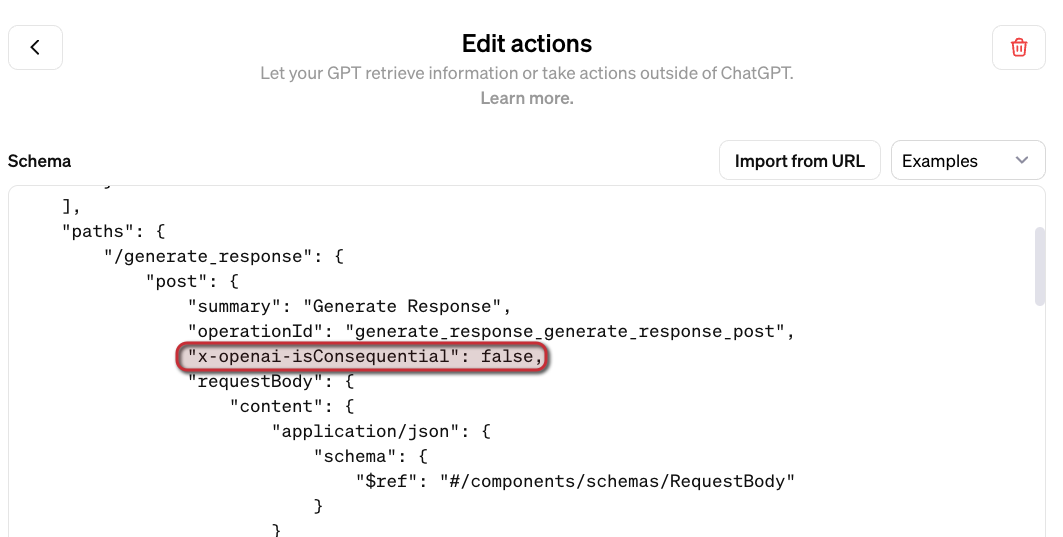
Take a look at the video below that shows how to create the GPT, including the configuration of the action and testing it.
Conclusion
Custom GPTs in ChatGPT open up a world of possibilities to offer personalised ChatGPT experiences. With custom actions, you can let the GPT do anything you want. In this tutorial, the custom action is an API call that answers the user’s question using Azure OpenAI with Azure AI Search as the provider of relevant context.
As long as you build and host an API and have an OpenAPI spec for your API, the possibilities are virtually limitless.
Note that custom GPTs with actions are not available in the ChatGPT app on mobile yet (end November, 2023). When that happens, it will open up all these capabilities on the go, including enabling voice chat. Fun stuff! 😀