Many enterprises have systems in place that take documents, possibly handwritten, that contain data that needs to be extracted. In this post, we will create an application that can extract data from documents that you upload. We will make use of an LLM, in this case gpt-4o. We will use model version 2024-08-06 and its new structured output capabilities. Other LLMs can be used as well.
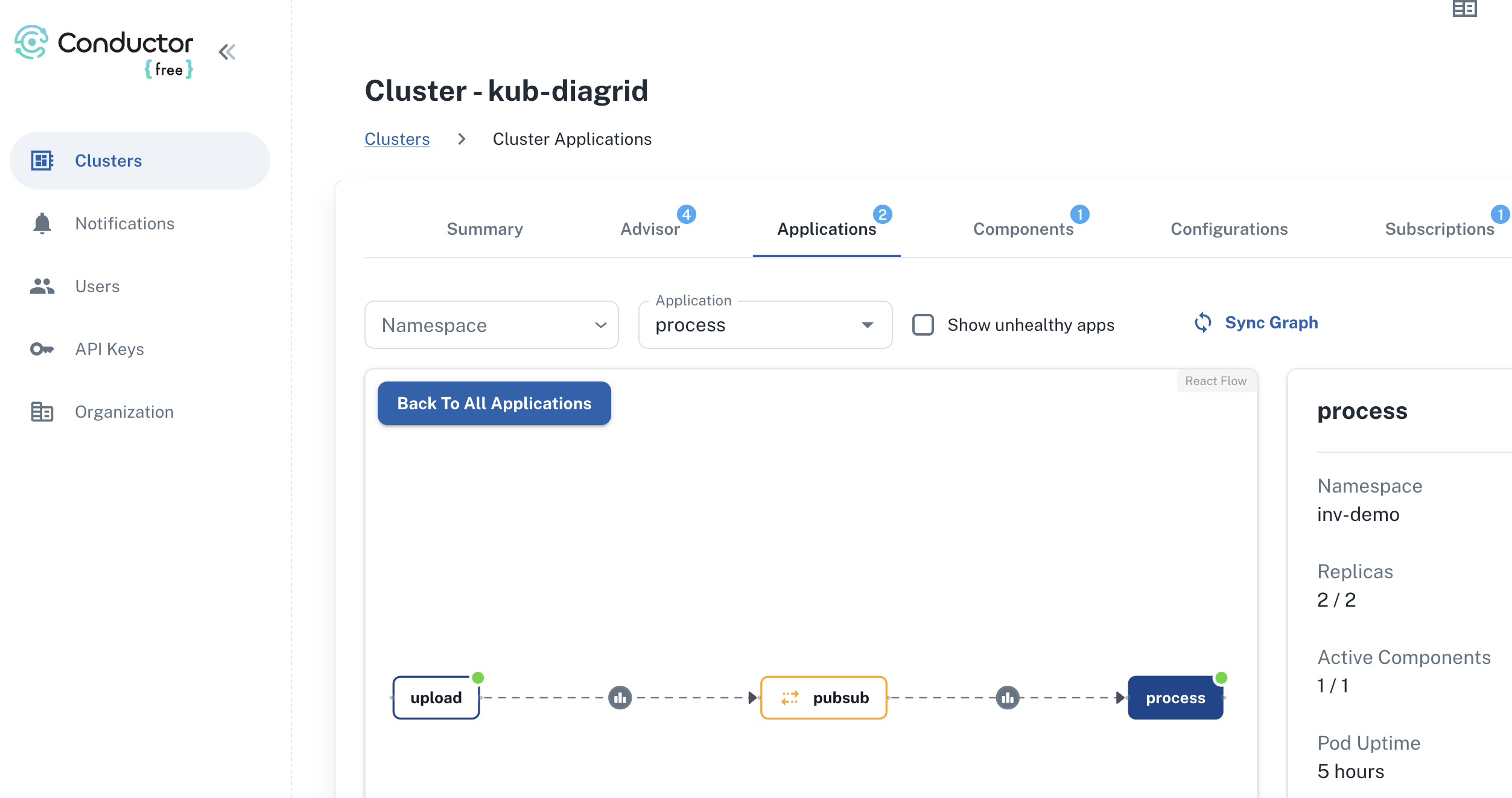
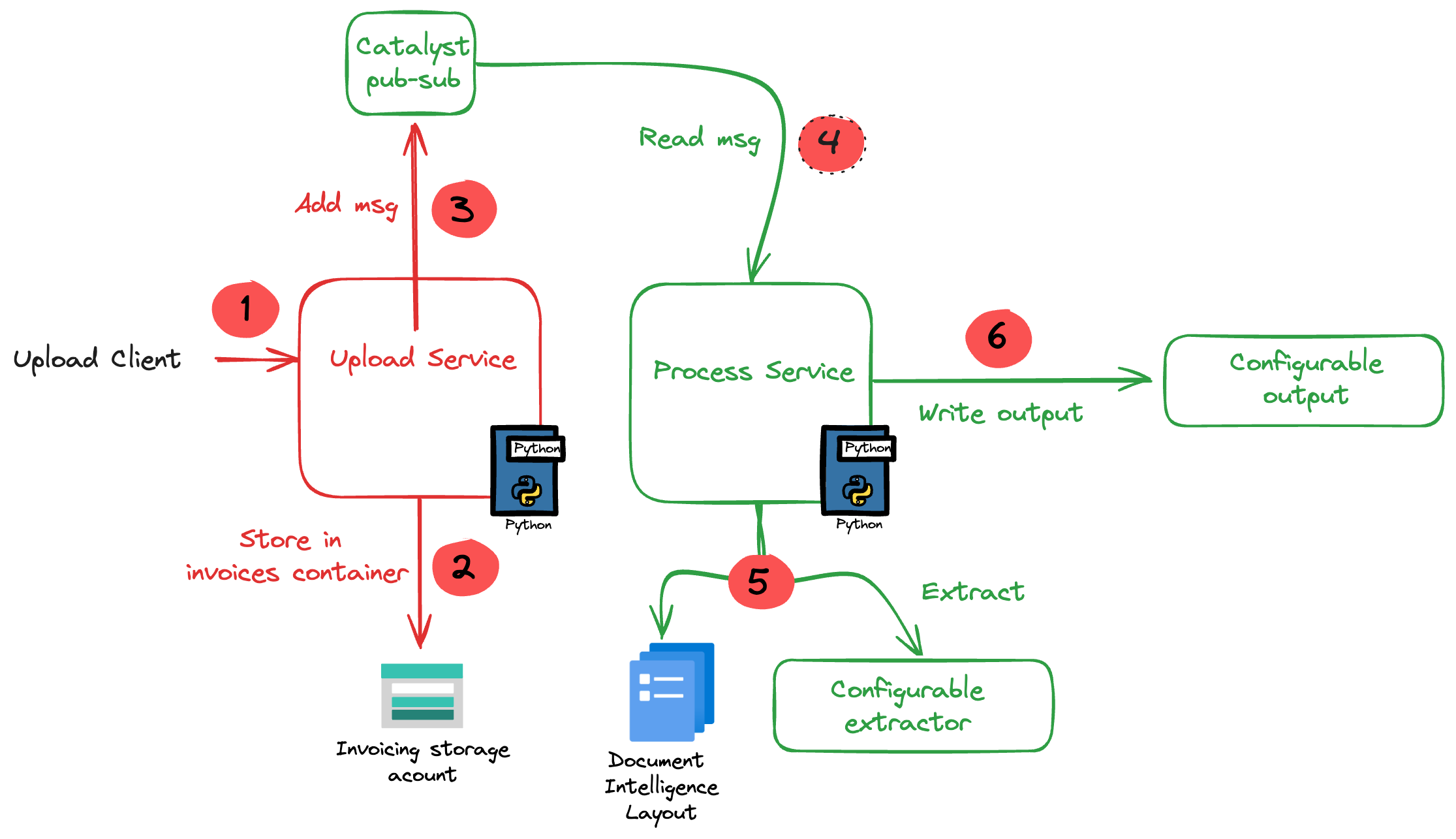
The core of the application is illustrated in the diagram below. The application uses more services than in the diagram. We will get to them later in this post.
Note: the LLM-based extraction logic in this project is pretty basic. In production, you need to do quite a bit more to get the extraction just right.
The flow of the application is as follows:
- A user or process submits a document to the upload service. This can be a pdf but other formats are supported as well.
- In addition to the document, a template is specified by name. A template contains the fields to extract, together with their type (str, bool, float). For example:
customer_name(str),invoice_total(float). - The upload service uploads the document to an Azure Storage account using a unique filename and preserves the extension.
- The upload service publishes a message to a topic on a pub/sub message broker. The message contains data such as the document url and the name of the template.
- The process service subscribes to the topic on the message broker and retrieves the message.
- It downloads the file from the storage account and sends it to Azure Document Intelligence to convert it to plain text.
- Using a configurable extractor, an LLM is used to extract the fields in the template from the document text. The sample code contains an OpenAI and a Groq extractor.
- The extracted fields are written to a configurable output handler. The sample code contains a CSV and JSONL handler.
In addition to a pub-sub broker, templates are stored in a state store. The upload service is the only service that interfaces with the state store. It provides an HTTP method that the process service can use to retrieve a template from the state store.
To implement pub-sub, the state store and method invocations, we will use Diagrid’s Catalyst instead of doing this all by ourselves.
What is Catalyst?
If you are familiar with Dapr, the distributed application runtime, Catalyst will be easy to understand. Catalyst provides you with a set of APIs, hosted in the cloud and compatible with Dapr to support you in building cloud-native, distributed applications. It provides several building blocks. The ones we use are below:
- request/reply: to support synchronous communication between services in a secure fashion
- publish/subscribe: to support asynchronous communication between services using either a broker provided by Catalyst or other supported brokers like Azure Service Bus
- key/value: allows services to save state in a key/value store. You can use the state store provided by Catalyst or other supported state stores like Azure Cosmos DB or an Azure Storage Account
The key to these building blocks is that your code stays the same if you swap the underlying message broker or key/value store. For example, you can start with Catalyst’s key/value store and later switch to Cosmos DB very easily. There is no need to add Cosmos DB libraries to your code. Catalyst will handle the Cosmos DB connectivity for you.
Important: I am referring mainly to Azure services here but Catalyst (and Dapr) support many services in other clouds as well!
Note that you do not need to install Dapr on your local machine or on platforms like Kubernetes when you use Catalyst. You only use the Dapr SDKs in your code and, when configured to do so, the SDK will connect to the proper APIs hosted in the cloud by Catalyst. In fact, you do not even need an SDK because the APIs can be used with plain HTTP or GRPC. Of course, using an SDK makes things a lot easier.
If you want to learn more about Catalyst, take a look at the following playlist: https://www.youtube.com/watch?v=7D7rMwJEMsk&list=PLdl4NkEiMsJscq00RLRrN4ip_VpzvuwUC. Lots of good stuff in there!
By doing all of the above in Catalyst we have a standardised approach that remains the same no matter the service behind it. We also get implementation best practices, for example for pub/sub. In addition, we are also provided with golden metrics and a UI to see how the application performs. All API calls are logged to aid in troubleshooting.
Let’s now take a look at the inner loop development process!
Scaffolding a new project
You need to sign up for Catalyst first. At the time of writing, Catalyst was in preview and not supported for production workloads. When you have an account, you should install the Diagrid CLI. The CLI is not just for Catalyst. It’s also used with Diagrid’s other products, such as Conductor.
With the CLI, you can create a new project, create services and application identities. For this post, we will use the UI instead.
In the Catalyst dashboard, I created a project called idpdemo:

Next, for each of my services (upload and process), we create an App ID. Each App ID has its own token. Services use the token to authenticate to the Catalyst APIs and use the services they are allowed to use.
The process App ID has the following configuration (partial view):
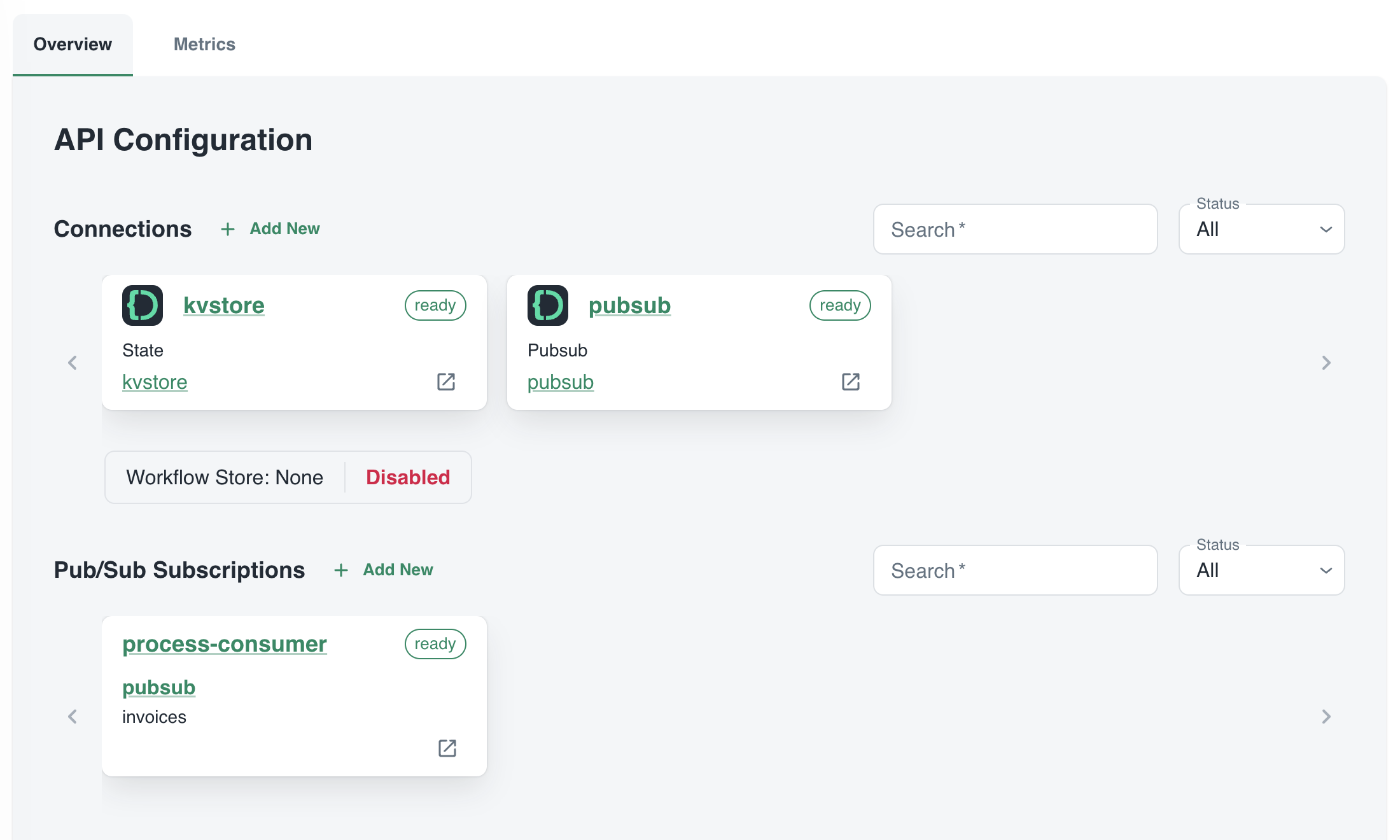
The process service interacts with both the Catalyst key/value store (kvstore) and the pub/sub broker (pubsub). These services need to be enabled as well. We will show that later. We can also see that the process service has a pub/sub subscription called process-consumer. Via that subscription, we have pub/sub messages delivered to the process service whenever the upload service sends a message to the pub/sub topic.
In Diagrid Services, you can click on the pub/sub and key/value store to see what is going on. For example, in the pub/sub service you can see the topics, the subscribers to these topics and the message count.

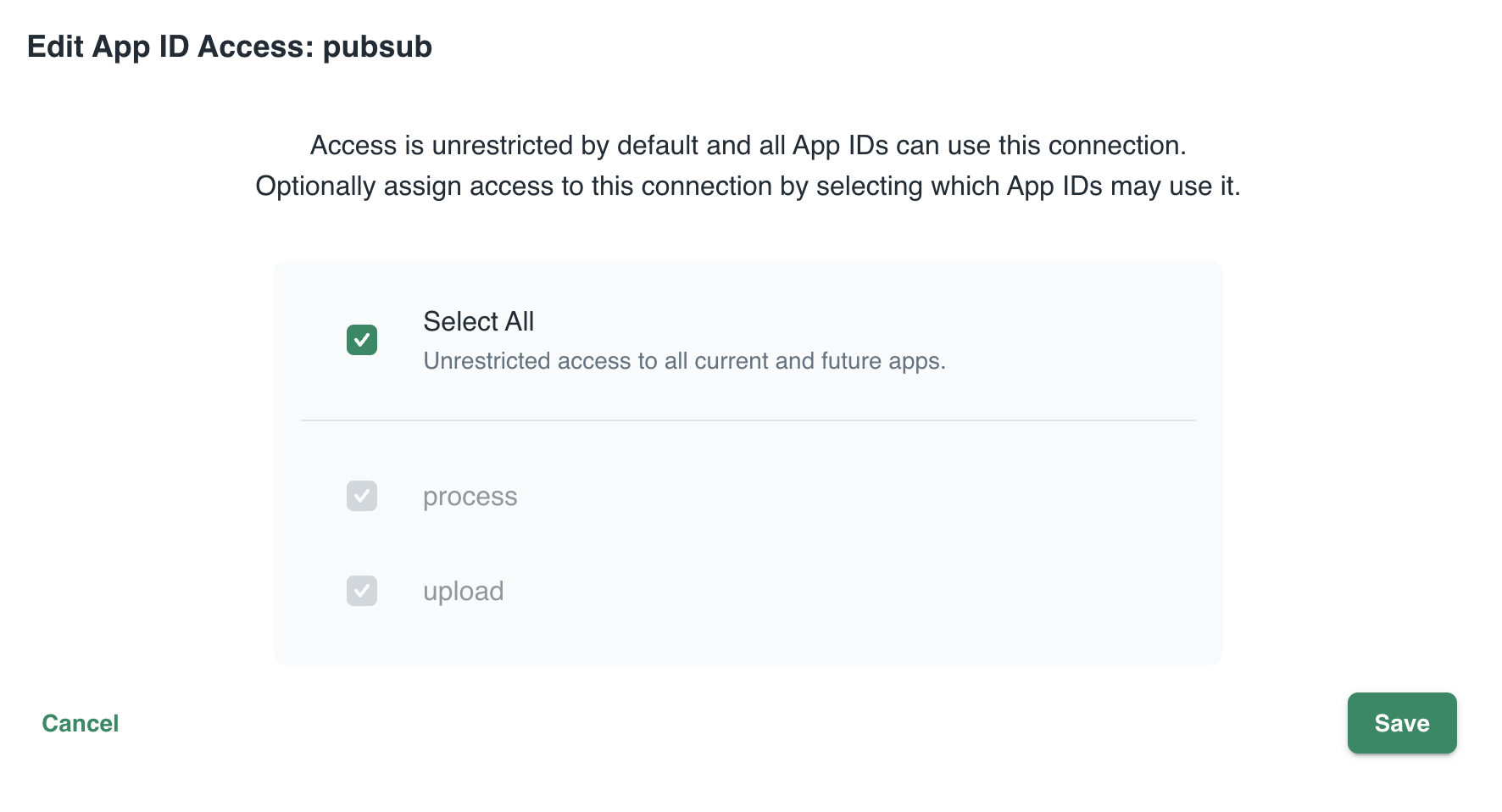
In Connections, you can see your services (represented by App ID upload and process) and their scope. In this case, all App IDs have access to all services. That can easily be changed:
Now that we have some understanding of App IDs, Diagrid services and connections, we can take a look at how to connect to Catalyst from code.
Important: in this post we only look at using request/reply, Diagrid pub/sub and key/value. Catalyst also supports workflow and bindings but they are not used in this post.
Connecting your code
All code is available on GitHub: https://github.com/gbaeke/catalyst
The upload service needs to connect to both the pub/sub broker and key/value store:
- Whenever a document is uploaded, it is uploaded to Azure Storage. When that succeeds, a message is put on the broker with the path of the file and a template name.
- Templates are created and validated by the upload service so that you can only upload files with a template that exists. Templates are written and read in the key/value store.
Before we write code, we need to provide the Dapr SDK for Python (we’ll only use the Python SDK here) the necessary connection information. It needs to know it should not connect to a Dapr sidecar but to Catalyst. You set these via environment variables:
- export DAPR_HTTP_ENDPOINT=”https://http-prid.api.cloud.diagrid.io”
- export DAPR_GRPC_ENDPOINT=”https://grpc-prid.api.cloud.diagrid.io”
- export DAPR_API_TOKEN=”your service API token”
These environment variables are automatically picked up and used by SDK to interact with the Catalyst APIs. The following code can be used to put a message on the pub/sub broker:
with DaprClient() as d:
try:
result = d.publish_event(
pubsub_name=pubsub_name,
topic_name=topic_name,
data=invoice.model_dump_json(),
data_content_type='application/json',
)
logging.info('Publish Successful. Invoice published: %s' %
invoice.path)
return True
except grpc.RpcError as err:
logging.error(f"Failed to publish invoice: {err}")
return FalseThis is the same code that you would use with Dapr on your local machine or in Kubernetes or Azure Container Apps. Like with Dapr, you need to specify the pubsub name and topic. Here that is pubsub and invoices as previously shown in the Catalyst UI. The data in the message is an instance of a Pydantic class that holds the path and template but converted to JSON.
The code below shows how to write to the state store (key/value store):
with DaprClient() as d:
try:
d.save_state(store_name=kvstore_name,
key=template_name, value=str(invoice_data))
except grpc.RpcError as err:
logging.error(f"Dapr state store error: {err.details()}")
raise HTTPException(status_code=500, detail="Failed to save template")This is of course very similar. We use the save_state method here and provide the store name (kvstore), key (template name) and value.
Let’s now turn to the process service. It needs to:
- be notified when there is a new message on the invoices topic
- check and retrieve the template by calling a method on the upload service
We only use two building blocks here: pub/sub and request/reply. The process service does not interact directly with the state store.
To receive a message, Catalyst needs a handler to call. In the pub/sub subscription, the handler (default route to be correct) is configured to be /process:

Our code that implements the handler is as follows (FastAPI):
@app.post('/process') # called by pub/sub when a new invoice is uploaded
async def consume_orders(event: CloudEvent):
# your code hereAs you can see, when Catalyst calls the handler, it passes in a CloudEvent. The event has a data field that holds the path to our document and the template name. The CloudEvent type is defined as follows:
# pub/sub uses CloudEvent; Invoice above is the data
class CloudEvent(BaseModel):
datacontenttype: str
source: str
topic: str
pubsubname: str
data: dict
id: str
specversion: str
tracestate: str
type: str
traceid: strIn the handler, you simply extract the expected data and use it to process the event. In our case:
- extract path and template from the data field
- download the file from blob storage
- send the file to Azure Document Intelligence to convert to text
- extract the details from the document based on the template; if the template contains fields like
customer_nameandinvoice_total, the LLM will try to extract that and return that content in JSON. - write the extracted values to JSON or CSV or any other output handler
Of course, we do need to extract the full template because we only have the template name. Let’s use the request/reply APIs to do that and call the template GET endpoint of the upload service via Catalyst:
def retrieve_template_from_kvstore(template_name: str):
headers = {'dapr-app-id': invoke_target_appid, 'dapr-api-token': dapr_api_token,
'content-type': 'application/json'}
try:
result = requests.get(
url='%s/template/%s' % (base_url, template_name),
headers=headers
)
if result.ok:
logging.info('Invocation successful with status code: %s' %
result.status_code)
logging.info(f"Template retrieved: {result.json()}")
return result.json()
except Exception as e:
logging.error(f"An error occurred while retrieving template from Dapr KV store: {str(e)}")
return NoneAs an example, we use the HTTP API here instead of the Dapr invoke API. It might not be immediately clear but Catalyst is involved in this process and will have information and metrics about these calls:

The full line represents request/reply (invoke) from process to upload as just explained. The dotted line represents pub/sub traffic where upload creates messages to be consumed by process.
Running the app
You can easily run your application locally using the Diagrid Dev CLI. Ensure you are logged in by running diagrid login. In the preview, with only one project, the default project should already be that one. Then simply run diagrid dev scaffold to generate a yaml file.
In my case, after some modification, my dev-{project-name}.yaml file looked like below:
project: idpdemo
apps:
- appId: process
disabled: true
appPort: 8001
env:
DAPR_API_TOKEN: ...
DAPR_APP_ID: process
DAPR_CLIENT_TIMEOUT_SECONDS: 10
DAPR_GRPC_ENDPOINT: https://XYZ.api.cloud.diagrid.io:443
DAPR_HTTP_ENDPOINT: https://XYZ.api.cloud.diagrid.io
OTHER ENV VARS HERE
workDir: process
command: ["python", "app.py"]
- appId: upload
appPort: 8000
env:
... similar
workDir: upload
command: ["python", "app.py"]
appLogDestination: ""
Of course, the file was modified with environment variables required by the code. For example the storage account key, Azure Document Intelligence key, etc…
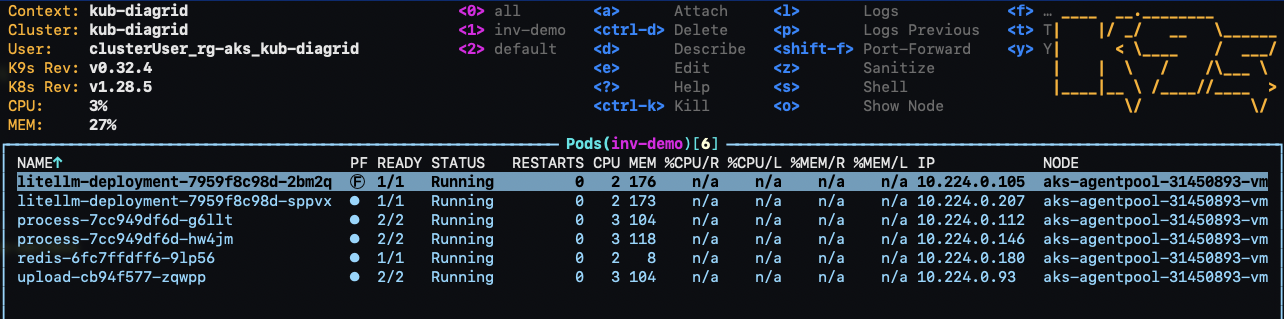
All you need to do now is to run diagrid dev start to start the apps. The result should be like below:
By default, your service logs are written to the console with a prefix for each service.
If you use the code in GitHub, check the README.md to configure the project and run the code properly. If you would rather run the code with Dapr on your local machine (e.g., if you do not have access to Catalyst) you can do that as well.
Conclusion
In this post, we have taken a look at Catalyst, a set of cloud APIs that help you to write distributed applications in a standard and secure fashion. These APIs are compatible with Dapr, a toolkit that has already gained quite some traction in the community. With Catalyst, we quickly built an application that can be used as a starter to implement an asynchronous LLM-based document extraction pipeline. I did not have to worry too much about pub/sub and key/value services because that’s all part of Catalyst.
What will you build with Catalyst?