Azure AI Agents Service simplifies building intelligent agents by combining advanced AI models, tools, and technology from Microsoft, OpenAI, and partners like Meta and Cohere. It enables integration with knowledge sources such as Bing, SharePoint, and Azure AI Search, and lets agents perform actions across Microsoft and third-party applications using Logic Apps, Azure Functions, and Code Interpreter. With Azure AI Foundry, you get an intuitive agent-building experience, backed by enterprise-grade features like customizable storage, private networking, secure authentication, and detailed observability through OpenTelemetry.
At the time of this writing (December 2024), Azure AI Foundry did not provide a user interface yet to create these agents in the portal. In this post, we will use the Azure AI Foundry SDK to create the agent from code.
You can find the code in this repository: https://github.com/gbaeke/agent_service/tree/main/agentui
How does it work?
The agent service uses the same wire protocol as the Azure OpenAI Assistants API. The Assistants API was developed as an alternative to the chat completions API. The big difference is that the Assistants API is stateful: your interactions with the AI model are saved as messages on a thread. You simply add messages to the thread for the model to respond.
For more information, check this video:
To get started, you need three things:
- An agent: the agent uses a model and instructions about how it should behave. In addition, you add knowledge sources and tools. Knowledge sources can be files you upload to the agent or existing sources such as files on SharePoint. Tools can be built-in tools like code interpreter or custom tools like any API or custom functions that you write.
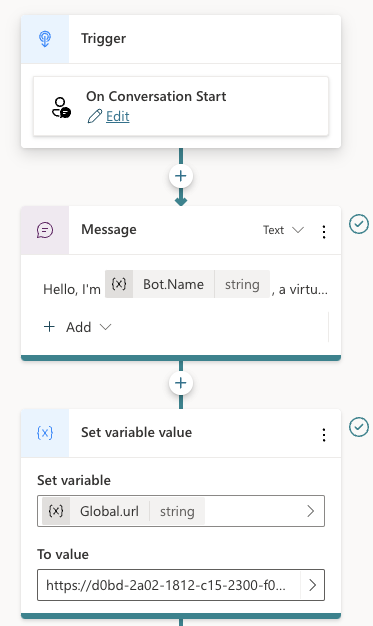
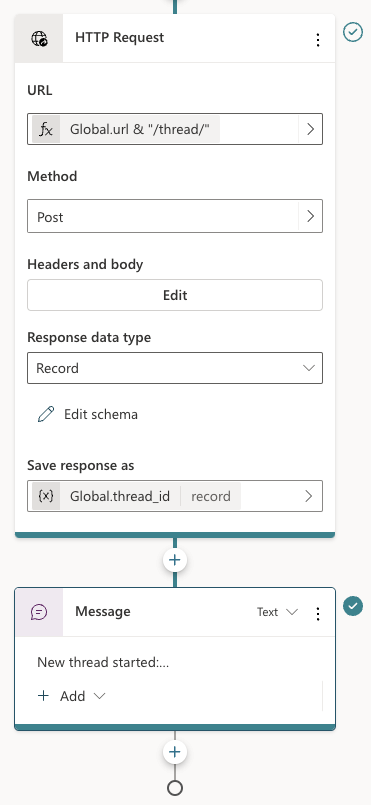
- A thread: threads receive messages from users and the assistant (the model) responds with assistant messages. In a chat application, each of the user’s conversations can be a thread. Note that threads are created, independent of an agent. The thread is associated with the agent when you add a message.
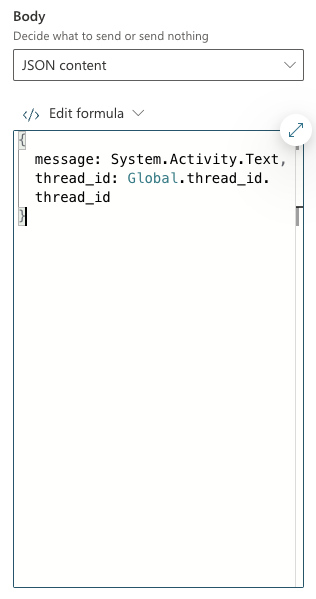
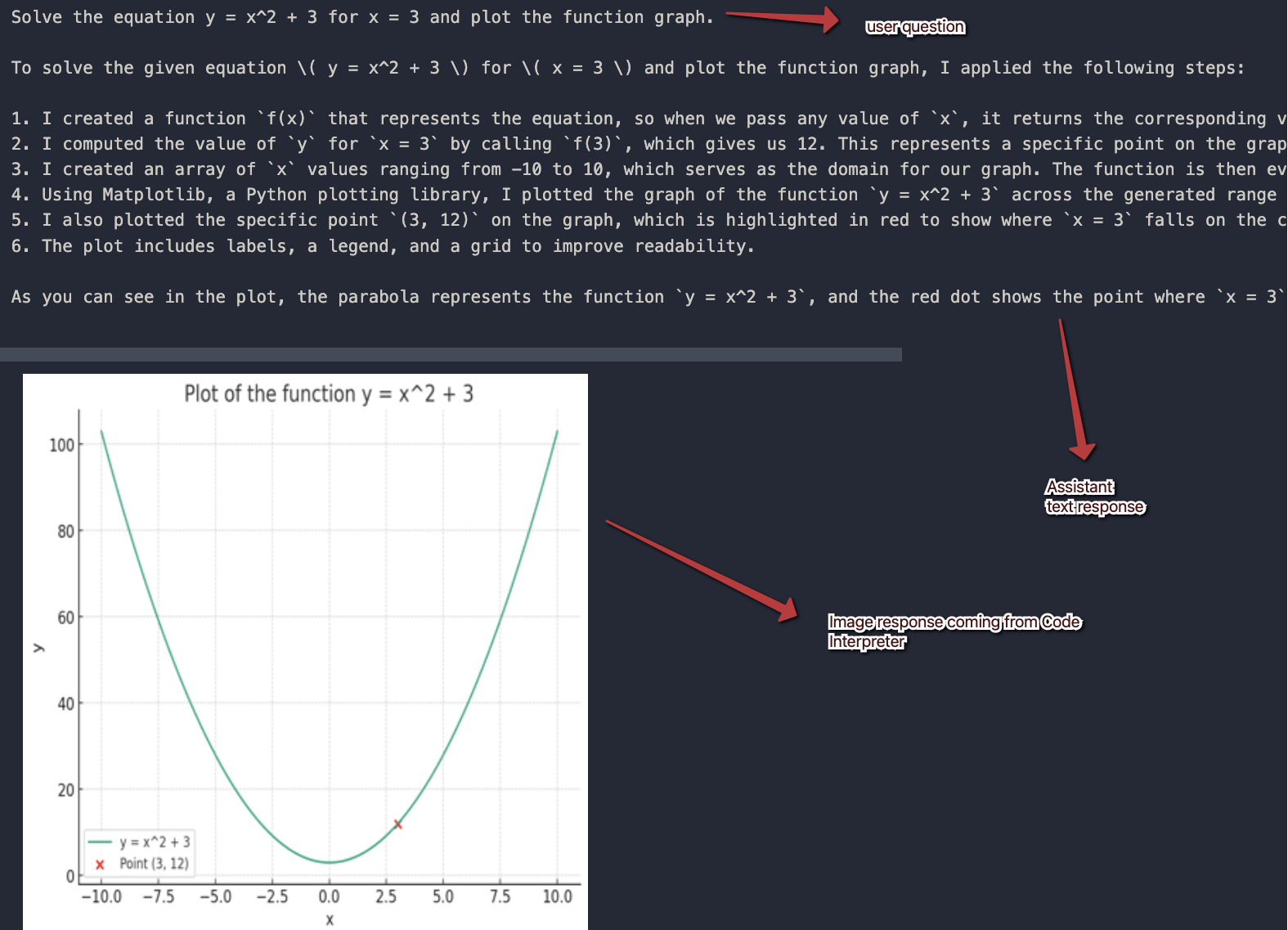
- Messages: you add messages to a thread and check the thread for new messages. Messages can contain both text and images. For example, if you use the code interpreter tool and you asked for a chart, the chart will be created and handed to you as a file id. To render the chart, you would need to download it first based on its id.
Creating the agent
Before we create the agent, we need to connect to our Azure AI Foundry project. To do that (and more), we need the following imports:
import os
from azure.ai.projects import AIProjectClient
from azure.ai.projects.models import CodeInterpreterTool
from azure.identity import DefaultAzureCredential
from fastapi import FastAPI
from typing import Dict
from azure.ai.projects.models import FunctionTool, ToolSet
from typing import Any, Callable, Set, Dict
from fastapi.middleware.cors import CORSMiddleware
from pydantic import BaseModel
import requests
import base64We will use the AIProjectClient to get a reference to an Azure AI Foundry project. We do that with the following code:
# Set up credentials and project client
credential = DefaultAzureCredential()
conn_str = os.environ["PROJECT_CONNECTION_STRING"]
project_client = AIProjectClient.from_connection_string(
credential=credential, conn_str=conn_str
)Note that we authenticate with Entra ID. On your local machine, ensure you are logged on via the Azure CLI with az login. Your account needs at least AI Developer access to the Foundry project.
You also need the connection string to your project. The code requires it in the PROJECT_CONNECTION_STRING environment variable. You can find the connection string in Azure AI Foundry:

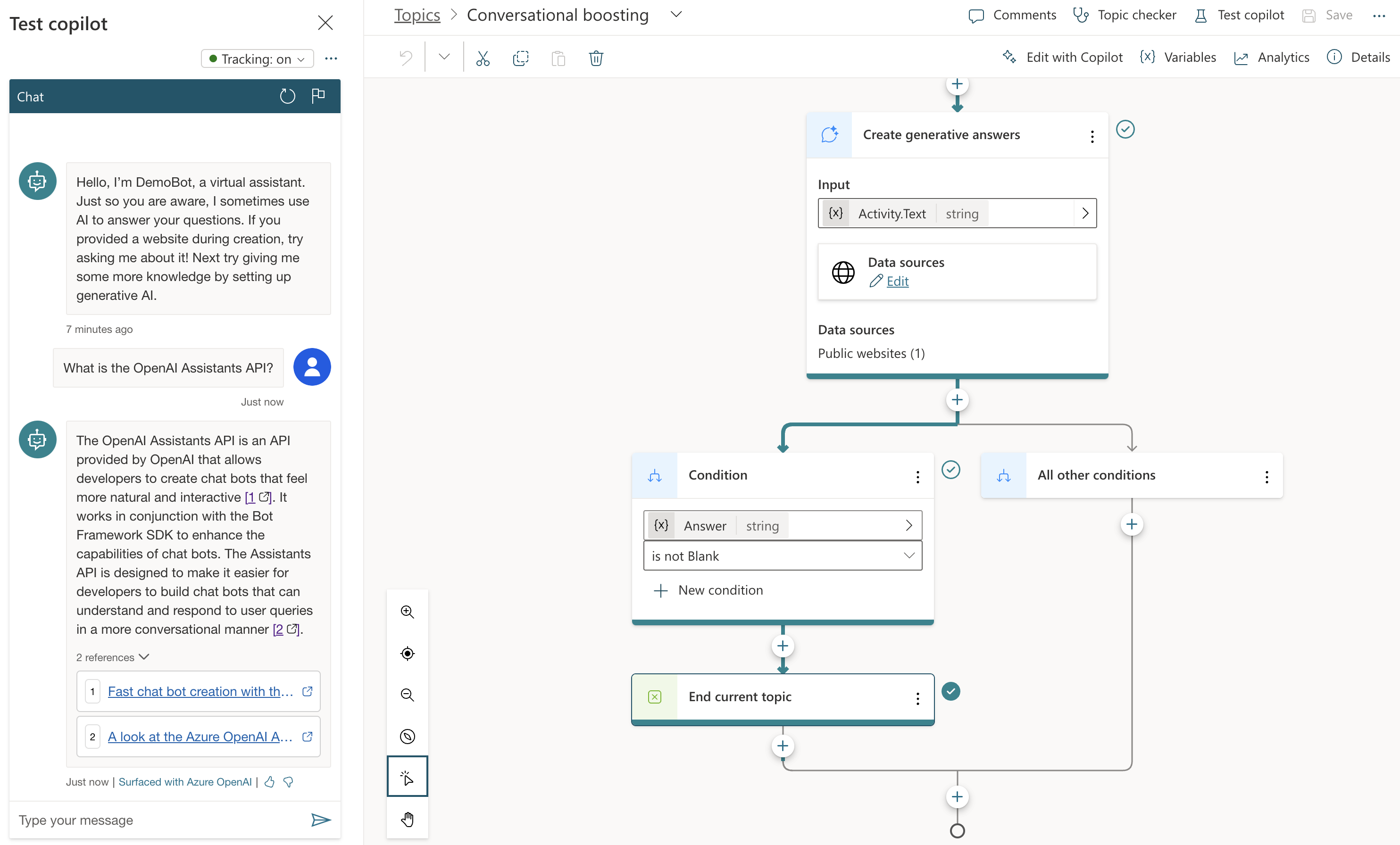
We can now create the agent with the following code:
agent = project_client.agents.create_agent(
model="gpt-4o-mini",
name="my-agent",
instructions="You are helpful agent with functions to turn on/off light and get temperature in a location. If location is not specified, ask the user.",
toolset=toolset
)Above, the agent uses gpt-4o-mini. You need to ensure that model is deployed in your Azure AI Foundry Hub. In our example, we also provide the assistant with tools. We will not provide it with knowledge.
What’s inside the toolset?
- built-in code interpreter tool: provides a way for the model to write Python code, execute it and provide the result back to the model; the result can be text and/or images.
- custom tools: in our case, custom Python functions to turn on/off lights and look up weather information in a location.
There are other tool types that we will not discuss in this post.
Adding tools
Let’s look at adding our own custom functions first. In the code, three functions are used as tools:
def turn_on_light(room: str) -> str:
return f"Light in room {room} turned on"
def turn_off_light(room: str) -> str:
return f"Light in room {room} turned off"
def get_temperature(location: str) -> str:
# check the github repo for the codeThe SDK provides helpers to turn these functions into tools the assistant understands:
user_functions: Set[Callable[..., Any]] = {
turn_on_light,
turn_off_light,
get_temperature
}
functions = FunctionTool(user_functions)
toolset = ToolSet()
toolset.add(functions)Now we need to add the built-in code interpreter:
code_interpreter = CodeInterpreterTool()
toolset.add(code_interpreter)Now we have a toolset with three custom functions and the code interpreter. This toolset is given to the agent via the toolset parameter.
Now that we have an agent, we need to provide a way to create a thread and add messages to the thread.
Creating a thread
We are creating an API so we will create and endpoint to create a thread:
@app.post("/threads")
def create_thread() -> Dict[str, str]:
thread = project_client.agents.create_thread()
return {"thread_id": thread.id}As discussed earlier, a thread is created as a separate entity. It is not associated with the agent when you create it. When we later add a message, the thread will be associated with the agent that should process the message.
Working with messages
Next, we will provide an endpoint that accepts a thread id and a message you want to add to it:
@app.post("/threads/{thread_id}/messages")
def send_message(thread_id: str, request: MessageRequest):
created_msg = project_client.agents.create_message(
thread_id=thread_id,
role="user",
content=request.message # Now accessing message from the request model
)
run = project_client.agents.create_and_process_run(
thread_id=thread_id,
assistant_id=agent.id
)
if run.status == "failed":
return {"error": run.last_error or "Unknown error"}
messages = project_client.agents.list_messages(thread_id=thread_id)
last_msg = messages.get_last_message_by_sender("assistant")
last_msg_text = last_msg.text_messages[0].text.value if last_msg.text_messages else None
last_msg_image = last_msg.image_contents[0].image_file if last_msg.image_contents else None
last_msg_image_b64 = None
if last_msg_image:
file_stream = project_client.agents.get_file_content(file_id=last_msg_image.file_id)
base64_encoder = base64.b64encode
byte_chunks = b"".join(file_stream) # Concatenate all bytes from the iterator.
last_msg_image_b64 = base64_encoder(byte_chunks).decode("utf-8")
return {"assistant_text": last_msg_text,
"assistant_image": last_msg_image_b64}The code is pretty self-explanatory. In summary, here is what happens:
- a message is created with the
create_messagemethod; the message is added to the specifiedthread_idas ausermessage - the thread is run on the agent specified by the
agent.id - to know if the run is finished, polling is used; the
create_and_process_runhides that complexity for you - messages are retrieved from the thread but only the last assistant message is used
- we extract the text and image from the message if it is present
- when there is an image, we use
get_file_contentto retrieve the file content from the API; that functions returns an Iterator of bytes that are joined together and base64 encoded - the message and image are returned
Testing the API
When we POST to the threads enpoint, this is the response:
{
"thread_id": "thread_meYRMrkRtUiI1u0ZGH0z7PEN"
}We can use that id to post to the messages endpoint. For example in a .http file:
POST http://localhost:8000/threads/thread_meYRMrkRtUiI1u0ZGH0z7PEN/messages
Content-Type: application/json
{
"message": "Create a sample bar chart"
}The response to the above request should be something like below:
{
"assistant_text": "Here is a sample bar chart displaying four categories (A to D) with their corresponding values. If you need any modifications or another type of chart, just let me know!",
"assistant_image": "iVBORw0KGgoAAAANSUhEUgAABpYAAARNCAYAAABYAnNeAAAAOXRFWHRTb2Z0d2FyZQBNYXRwbG90bGliIHZlcnNpb24zLjQuMywgaHR0cHM6Ly9tYXRwbG90bGliLm9yZy/MnkTPAAAACXBIWXMAAB7CAAAewgFu0HU+AADWf0lEQ..."
}
In this case, the model determined that the code interpreter should be used to create the sample bar chart. When you ask for something simpler, like the weather, you get the following response:
{
"assistant_text": "The current temperature in London is 11.4°C. If you need more information or updates, feel free to ask!",
"assistant_image": null
}In this case, our custom weather function was used to answer. The assistant determines what tools should be used to provide an answer.
Integration in a web app
The GitHub repository contains a sample UI to try the API:

Beautiful, is it not? 😂
Conclusion
The Azure AI Agent service makes it relatively easy to create an agent that has access to knowledge and tools. The assistant decides on its own how to use the knowledge and tools. However, you can steer the assistant via its instructions and influence how the assistant behaves.
The SDK makes it easy to add your own custom functions as tools, next to the built-in tools that it supports. Soon, there will be an Agent Service user interface in Azure AI Foundry. You will be able to create agents in code that reference the agents you have built in Foundry.
To try it for yourself, use the code in the GitHub repo. Note that the code is demo code with limited error handling. It’s merely meant to demonstrate first steps.
Enjoy and let me know what you build with it! 😉