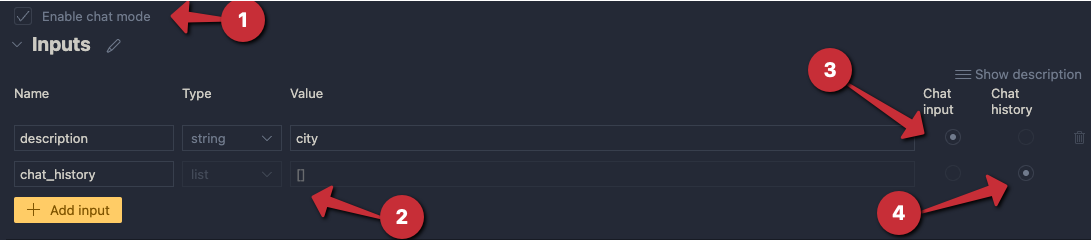
In two previous blog posts, I wrote an introduction to the Azure OpenAI Assistants API and how to work with custom functions. In this post, we will take a look at an assistant that can answer questions about documents. We will create an HR Assistant that has access to an HR policy document. In addition, we will provide a custom function that employees can use to request a raise.
Retrieval
The OpenAI Assistants API (not the one in Azure) supports a retrieval tool. You can simply upload one or more documents, turn on retrieval and you are good to go. The screenshot below shows the experience on https://platform.openai.com:

The important parts above are:
- the Retrieval tool was enabled
- Innovatek.pdf was uploaded, making it available to the Retrieval tool
To test the Assistant, we can ask questions in the Playground:

When asked about company cars, the assistant responds with content from the uploaded pdf file. After upload, OpenAI converted the document to text, chunked it and stored it in vector storage. I believe they even use Azure AI Search to do so. At query time, the vector store returns one or more pieces of text related to the question to the assistant. The assistant uses those pieces of text to answer the user’s question. It’s a typical RAG scenario. RAG stands for Retrieval Augmented Generation.
At the time of writing (February, 2024), the Azure OpenAI Assistants API did not support the retrieval tool. You can upload files but those files can only be used by the code_interpreter tool. That tool can also look in the uploaded files to answer the query but that is very unreliable and slow so it’s not recommended to use it for retrieval tasks.
Can we work around this limitation?
The Azure OpenAI Assistants API was in preview when this post was written. While in preview, limitations are expected. More tools like Web Search and Retrieval will be added as the API goes to general availability.
To work around the limitation, we can do the following ourselves:
- load and chunk our PDF
- store the chunks, metadata and embeddings in an in-memory vector store like Chroma
- create a function that takes in a query and return chunks and metadata as a JSON string
- use the Assistant API function calling feature to answer HR-related questions using that function
Let’s see how that works. The full code is here: https://github.com/gbaeke/azure-assistants-api/blob/main/files.ipynb
Getting ready
I will not repeat all code here and refer to the notebook. The first code block initialises the AzureOpenAI client with our Azure OpenAI key, endpoint and API version loaded from a .env file.
Next, we setup the Chroma vector store and load our document. The document is Innovatek.pdf in the same folder as the notebook.
from langchain_community.document_loaders import PyPDFLoader
from langchain_openai import AzureOpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
pdf = PyPDFLoader("./Innovatek.pdf").load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
documents = text_splitter.split_documents(pdf)
print(documents)
print(len(documents))
db = Chroma.from_documents(documents, AzureOpenAIEmbeddings(client=client, model="embedding", api_version="2023-05-15"))
# query the vector store
query = "Can I wear short pants?"
docs = db.similarity_search(query, k=3)
print(docs)
print(len(docs))
If you have ever used LangChain before, this code will be familiar:
- load the PDF with PyPDFLoader
- create a recursive character text splitter that splits text based on paragraphs and words as much as possible; check out this notebook for more information about splitting
- split the PDF in chunks
- create a Chroma database from the chunks and also pass in the embedding model to use; we use the OpenAI embedding model with a deployment name of embedding; you need to ensure an embedding model with that name is deployed in your region
- with the db created, we can use the
similarity_searchmethod to retrieve 3 chunks similar to the query Can I wear short pants? This returns an array of objects of type Document with properties likepage_contentandmetadata.
Note that you will always get a response from this similarity search, no matter the query. Later, the assistant will decide if the response is relevant.
We can now setup a helper function to query the document(s):
import json
# function to retrieve HR questions
def hr_query(query):
docs = db.similarity_search(query, k=3)
docs_dict = [doc.__dict__ for doc in docs]
return json.dumps(docs_dict)
# try the function; docs array as JSON
print(hr_query("Can I wear short pants?"))
We will later pass the results of this function to the assistant. The function needs to return a string, in this case a JSON dump of the documents array.
Now that we have this setup, we can create the assistant.
Creating the assistant
In the notebook, you will see some sample code that uploads a document for use with an assistant. We will not use that file but it is what you would do to make the file available to the retrieval tool.
In the client.beta.assistants.create method, we provide instructions to tell the assistant what to do. For example, to use the hr_query function to answer HR related questions.
The tools parameter shows how you can provide functions and tools in code rather than in the portal. In our case, we define the following:
- the
request_raisefunction: allows the user to request a raise, the assistant should ask the user’s name if it does not know; in the real world, you would use a form of authentication in your app to identify the user - the
hr_queryfunction: performs a similarity search with Chroma as discussed above; it calls our helper functionhr_query - the
code_interpretertool: needed to avoid errors because I uploaded a file and supply the file ids via thefile_idsparameter.
If you check the notebook, you should indeed see a file_ids parameter. When the retrieval tool becomes available, this is how you provide access to the uploaded files. Simply uploading a file is not enough, you need to reference it. Instead of providing the file ids in the assistant, you can also provide them during a thread run.
⚠️ Note that we don’t need the file upload, code_interpreter and file_ids. They are provided as an example of what you would do when the retrieval tool is available.
Creating a thread and adding a message
If you have read the other posts, this will be very familiar. Check the notebook for more information. You can ask any question you want by simply changing the content parameter in the client.beta.threads.messages.create method.
When you run the cell that adds the message, check the run’s model dump. It should indicate that hr_query needs to be called with the question as a parameter. Note that the model can slightly change the parameter from the original question.
⚠️ Depending on the question, the assistant might not call the function. Try a question that is unrelated to HR and see what happens. Even some HR-related questions might be missed. To avoid that, the user can be precise and state the question is HR related.
Call function(s) when necessary
The code block below calls the hr_query or request_raise function when indicated by the assistant’s underlying model. For request_raise we simply return a string result. No real function gets called.
if run.required_action:
# get tool calls and print them
# check the output to see what tools_calls contains
tool_calls = run.required_action.submit_tool_outputs.tool_calls
print("Tool calls:", tool_calls)
# we might need to call multiple tools
# the assistant API supports parallel tool calls
# we account for this here although we only have one tool call
tool_outputs = []
for tool_call in tool_calls:
func_name = tool_call.function.name
arguments = json.loads(tool_call.function.arguments)
# call the function with the arguments provided by the assistant
if func_name == "hr_query":
result = hr_query(**arguments)
elif func_name == "request_raise":
result = "Request sumbitted. It will take two weeks to review."
# append the results to the tool_outputs list
# you need to specify the tool_call_id so the assistant knows which tool call the output belongs to
tool_outputs.append({
"tool_call_id": tool_call.id,
"output": json.dumps(result)
})
# now that we have the tool call outputs, pass them to the assistant
run = client.beta.threads.runs.submit_tool_outputs(
thread_id=thread.id,
run_id=run.id,
tool_outputs=tool_outputs
)
print("Tool outputs submitted")
# now we wait for the run again
run = wait_for_run(run, thread.id)
else:
print("No tool calls identified\n")
After running this code in response to the user question about company cars, let’s see what the result is:

The assistant comes up with this response after retrieving several pieces of text from the Chroma query. With the retrieval tool, the response would be similar with one big advantage. The retrieval tool would include sources in its response for you to display however you want. Above, I have simply asked the model to include the sources. The model will behave slightly differently each time unless you give clear instructions about the response format.
Retrieval and large amounts of documents
The retrieval tool of the Assistants API is not built to deal with massive amounts of data. The number of documents and sizes of those documents are limited.
In enterprise scenarios with large knowledge bases, you would use your own search indexes and a data processing pipeline to store your content in these indexes. For Azure customers, the indexes will probably be stored in Azure AI Search, which supports hybrid (text & vector) search plus semantic reranking to come up with the most relevant results.
Conclusion
The Azure OpenAI Assistants API will make it very easy to retrieve content from a limited amount of uploaded documents once the retrieval tool is added to the API.
To work around the missing retrieval tool today, you can use a simple vector storage solution and a custom function to achieve similar results.