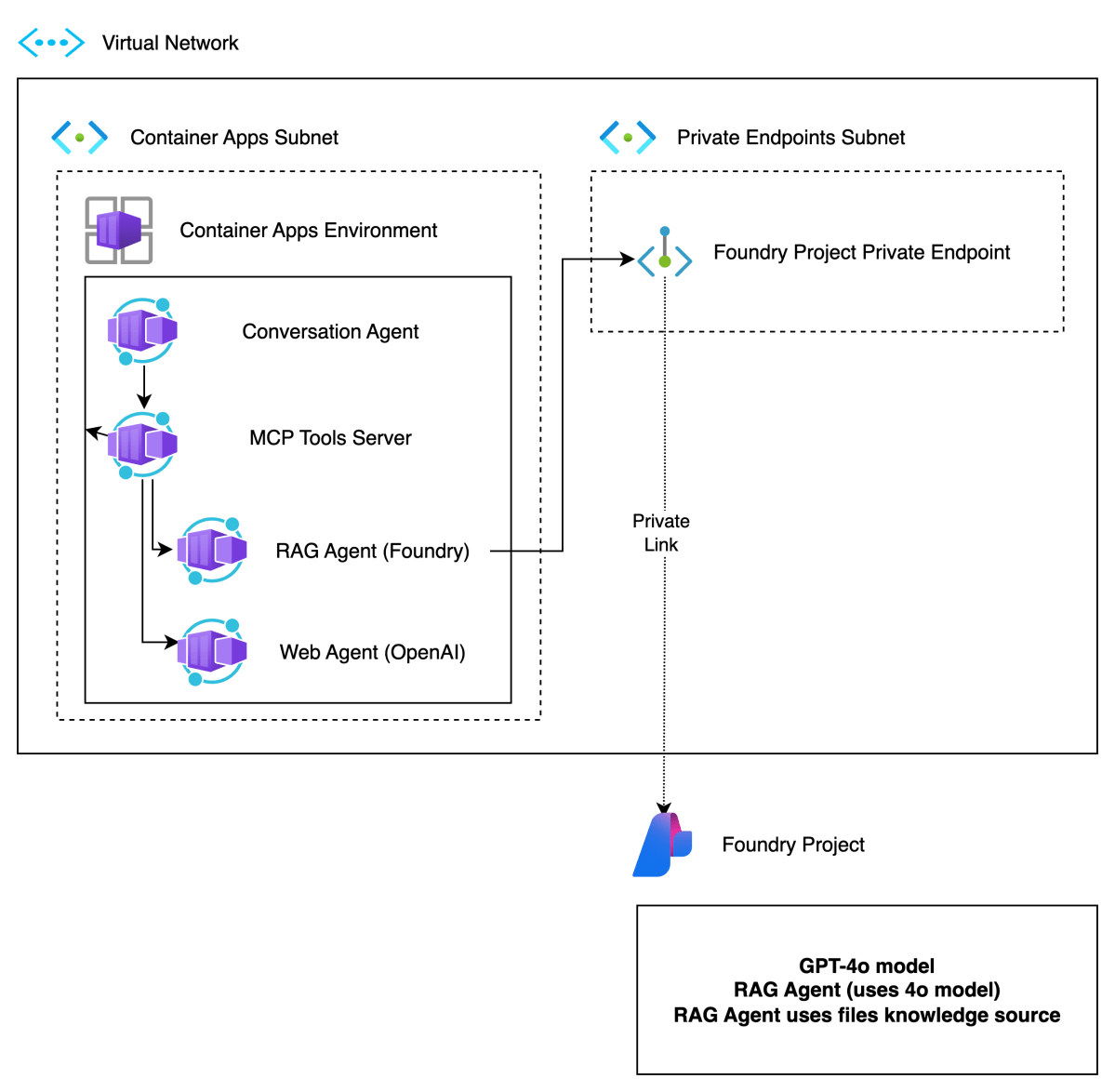
In previous posts, I discussed multi-agent solutions and the potential use of Google’s Agent2Agent protocol (A2A). In this post, we will deploy the infrastructure for an end-to-end solution like follows:

Here’s a short description of the components.
| Component | Description |
| Foundry Project | Basic Foundry project with a private endpoint. The private endpoint ensures private communication between the RAG Agent container and the Azure Foundry agent. |
| Virtual Network | Provides subnet to integrate Azure Container Apps Environment in a private network. This allows container apps to connect to Azure AI Foundry privately. |
| Container Apps Environment | Integrated in our private network. Hosts Container Apps. |
| Container Apps | Container apps for conversation agent, MCP server, RAG agent and web agent. Only the conversation agent is publicly available. |
In what follows, we will first provide more information about Azure AI Foundry and then proceed to deploy all components except the Azure Container Apps themselves. We will deploy the actual app components in a follow-up post.
Azure AI Foundry Project
Azure AI Foundry is Microsoft’s enterprise platform for building, deploying, and managing AI applications—especially those using large language models (LLMs) and generative AI. It brings together everything you need: production-ready infrastructure, access to powerful models from providers like OpenAI, Mistral, and Meta, and tools for customization, monitoring, and scaling—all in one unified environment.
It’s designed to support the full AI development lifecycle:
- Explore and test models and services
- Build and customize applications or agents
- Deploy to production
- Monitor, evaluate, and improve performance
You can work either through the Azure AI Foundry portal or directly via SDKs in your preferred development environment.
You will do your work in a project. When you create a project in Azure AI Foundry, you’ll choose between two types:
Foundry Project
This type is recommended for most cases and is what we will use to define our RAG agent. Agents in projects are generally available (GA). You deploy models like gpt-4o directly to the project. There is no need to create a connection to an Azure OpenAI resource. It can be configured with a private endpoint to ensure private communication.
This matches exactly with our needs. Note that we will deploy a basic Foundry environment with a private endpoint and not a standard environment. For more information about basic versus standard, check the Foundry documentation.
Later, when we create the resources via Bicep, two resources will be created:
- The Azure AI Foundry resource: with private endpoint
- The Azure AI Foundry Project: used to create our RAG agent

Hub-based Project
This type has some additional options like Prompt Flow. However, agents in hub-based projects are not generally available at the time of writing. A hub-based project is not the best match for our needs here.
⚠️ In general, always use an Foundry Project versus a Hub-based Project unless you need a specific feature that, at the time of creation, is not yet available in Foundry projects.
As explained above, a Foundry project is part of an AI Foundry resource. Here is the resource in the portal (hub-based projects are under AI Hubs):

Inside the resource, you can create a project. The above resource has one project:

To work with your project, you can click Go to Azure AI Foundry portal in the Overview tab:

In the Foundry Portal, you can proceed to create agents. However, if you have enabled a private endpoint, ensure you can access your Azure virtual network via a jump host or VPN. If that is not possible, allow your IP to access the Foundry resource in the Networking section of the resource. When you do not have access, you will see the following error:

⚠️ Even after giving access, it will take a while for the change to propagate.
If you have access, you will see the following screen to add and configure agents:

Deployment with Bicep
You can check https://github.com/gbaeke/multi_agent_aca/tree/main/bicep to find Bicep files together with a shell script to deploy the resources. Also check the README for more information.
In Bicep, you first create an account (type is Microsoft.CognitiveServices/accounts). This matches the fndry-a2a resource in one of the screenshots above. In a later step, you add the project. The snippet below shows how the account gets created:
resource account 'Microsoft.CognitiveServices/accounts@2025-04-01-preview' = {
name: aiFoundryName
location: location
identity: {
type: 'SystemAssigned'
}
kind: 'AIServices'
sku: {
name: 'S0'
}
properties: {
// Networking
publicNetworkAccess: 'Enabled'
networkAcls: {
bypass: 'AzureServices'
defaultAction: 'Deny'
ipRules: [
{
value: 'IP address'
}
]
}
// Specifies whether this resource support project management as child resources, used as containers for access management, data isolation, and cost in AI Foundry.
allowProjectManagement: true
// Defines developer API endpoint subdomain
customSubDomainName: aiFoundryName
// Auth
disableLocalAuth: false
}
}
It’s at this level you block public network access. The private endpoint and related network resources are created in other sections of the Bicep file.
Once you have this account, you can create the project. This matches with the fndry-a2a-proj project in one of the screenshots above. Here is the Bicep snippet:
resource project 'Microsoft.CognitiveServices/accounts/projects@2025-04-01-preview' = {
name: defaultProjectName
parent: account
location: location
identity: {
type: 'SystemAssigned'
}
properties: {}
}
Later, we will create agents in this project. However, an agent needs a supported model. In this case, we will use gpt-4o-mini so we need to deploy it:
resource modelDeployment 'Microsoft.CognitiveServices/accounts/deployments@2024-10-01'= {
parent: account
name: 'gpt-4o-mini'
sku : {
capacity: 1
name: 'GlobalStandard'
}
properties: {
model:{
name: 'gpt-4o-mini'
format: 'OpenAI'
version: '2024-07-18'
}
}
}
⚠️ Above, a capacity of 1 only allows for 1000 tokens per minute. You will probably want to increase that. If not, you run into issues when you test your agents because you will quickly hit the limit.
In the Foundry Portal, the model is shown as follows:

I will not go into the rest of the Bicep code. Most of it is network related (network, subnets, private endpoint, private DNS, DNS network links, etc..).
Creating the RAG Agent
Although we can create the agent using the Foundry SDK, we will create and test it via the Foundry Portal. As a first step, create or modify an agent. You might get a question first about the model you want to use with your agents.
In your agent, do the following:
- give the agent a name
- select a model from the list of deployed models
- set instructions
I used the following instructions:
You retrieve information about Contoso projects using your knowledge tools. Always use your knowledge tools to answer the user. If you cannot find the answer via tools, respond you do not know.

Next, scroll down and click + Add next to Knowledge. You will see the following screen:

Select the Files tool and upload the files from https://github.com/gbaeke/multi_agent_aca/tree/main/project_descriptions. Use git clone https://github.com/gbaeke/multi_agent_aca.git to grab those files.

After selecting the local files, click Upload and Save to upload these files so the agent can search them. Behind the scenes, the files are chunked, chunks are vectorized and stored in a vector database. However, this is all hidden from you. Your agent configuration should now show the knowledge tool:

You should now test your agent. At the top of the configuration section, there is a Try in Playground link.
When I ask about EduForge, I get the following:

When you click View Run Info (at the end of the response), the use of the tool should be shown in the trace:

If this works, you have a simple agent in Foundry that has access to a file_search tool to perform RAG (retrieval-augmented generation).
Wrapping up
We have now deployed the RAG agent with Azure AI Foundry. We created a Foundry resource in Azure with a private endpoint. The Foundry resource has one project within it. The project contains our RAG agent.
But remember, we want to wrap this agent with Google’s Agent2Agent. To achieve that, we will deploy the A2A server that uses the Foundry agent as a container in the Container Apps Environment.
We will take a look at how that works in a next post. In that post, we will use these agents as tools via MCP and provide the MCP tools to our conversation agent. The conversation agent will use Semantic Kernel.
Stay tuned! 😊




