-
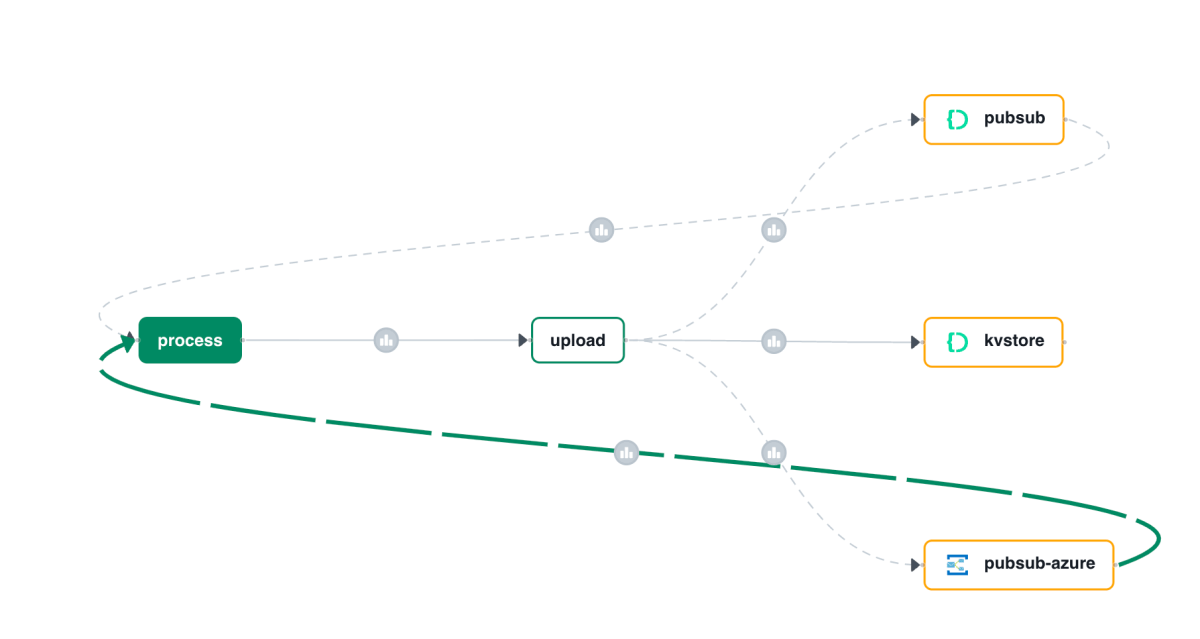
Using your own message broker with Diagrid Catalyst
In a previous post, I wrote about Diagrid Catalyst. Catalyst provides services like pub/sub and state stores to support the developer in writing distributed applications. In the post, we discussed a sample application that processes documents and extracts fields with an LLM (gpt-4o structured extraction). Two services, upload and process, communicate via the pub/sub pattern.… Read more
-

Writing an multi-service document extractor with the help of Diagrid’s Catalyst
Many enterprises have systems in place that take documents, possibly handwritten, that contain data that needs to be extracted. In this post, we will create an application that can extract data from documents that you upload. We will make use of an LLM, in this case gpt-4o. We will use model version 2024-08-06 and its… Read more
-
Token consumption in Microsoft’s Graph RAG
In the previous post, we discussed Microsoft’s Graph RAG implementation. In this post, we will take a look at token consumption to query the knowledge graph, both for local and global queries. Note: this test was performed with gpt-4o. A few days after this blog post, OpenAI released gpt-4o-mini. Initital tests with gpt-4o-mini show that… Read more
-
Trying out Microsoft’s Graph RAG
Whenever we build applications on top of LLMs such as OpenAI’s gpt-4o, we often use the RAG pattern. RAG stands for retrieval augmented generation. You use it to let the LLM answer questions about data it has never seen. To answer the question, you retrieve relevant information and hand it over to the LLM to… Read more
-

Embracing the Age of AI Transformation: A New Era for Innovation and Expertise
⚠️ This is an AI-generated article based on a video to transcript generator I created to summarise Microsoft Build sessions. This article is used as an example for a LinkedIn post. This article is based on the Microsoft Build keynote delivered on Tuesday, May 21st, 2024. It was created with gpt-4o. The post is unedited… Read more
-

Load balancing OpenAI API calls with LiteLLM
If you have ever created an application that makes calls to Azure OpenAI models, you know there are limits to the amount of calls you can make per minute. Take a look at the settings of a GPT model below: Above, the tokens per minute (TPM) rate limit is set to 60 000 tokens. This… Read more
-
Subscribe
Subscribed
Already have a WordPress.com account? Log in now.
