
In a previous post, we looked at creating a Copilot declarative agent. The agent had one custom action that called the JSONPlaceholder API. Check that post for an introduction to what these agents can do. Using a dummy, unauthenticated API is not much fun so let’s take a look at doing the same for a custom API that requires authentication.
Python API with authentication
The API we will create has one endpoint: GET /sales. It’s implemented as follows:
@app.get("/sales/", dependencies=[Depends(verify_token)])
async def get_sales():
"""
Retrieve sales data.
Requires Bearer token authentication.
"""
return {
"status": "success",
"data": generate_sample_sales_data()
}The data is generated by the generate_sample_sales_data function. It just generates random sales data. You can check the full code on GitHub. The important thing here is that we use bearer authentication with a key.
When I hit the /sales endpoint with a wrong key, a 401 Unauthorized is raised:

With the correct key, the /sales endpoint returns the random data:

Running the API
To make things easy, we will run the API on the local machine and expose it with ngrok. Install ngrok using the instructions on their website. If you cloned the repo, go to the api folder and run the commands below. Run the last command from a different terminal window.
pip install -r requirements.txt
python app.py
ngrok http 8000Note: you can also use local port forwarding in VS Code. I prefer ngrok but if you do not want to install it, simply use the VS Code feature.
In the terminal where you ran ngrok, you should see something like below:

Ngrok has a nice UI to inspect the calls via the web interface at http://localhost:4040:

Before continuing, ensure that the ngrok forwarding URL (https://xyz.ngrok-free.app) responds when you hit the /sales endpoint.
Getting the OpenAPI document
When you create a FastAPI API, it generates OpenAPI documentation that describes all the endpoints. The declarative agent needs that documentation to configure actions.
For the above API, that looks like below. Note that this is not the default document. It was changed in code.
{
"openapi": "3.0.0",
"info": {
"title": "Sales API",
"description": "API for retrieving sales data",
"version": "1.0.0"
},
"paths": {
"/sales/": {
"get": {
"summary": "Get Sales",
"description": "Retrieve sales data.\nRequires Bearer token authentication.",
"operationId": "get_sales_sales__get",
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {
}
}
}
}
}
}
},
"/": {
"get": {
"summary": "Root",
"description": "Root endpoint - provides API information",
"operationId": "root__get",
"responses": {
"200": {
"description": "Successful Response",
"content": {
"application/json": {
"schema": {
}
}
}
}
}
}
}
},
"components": {
"securitySchemes": {
"BearerAuth": {
"type": "http",
"scheme": "bearer"
}
}
},
"servers": [
{
"url": "https://627d-94-143-189-241.ngrok-free.app",
"description": "Production server"
}
]
}The Teams Toolkit requires OpenAPI 3.0.x instead of 3.1.x. By default, recent versions of FastAPI generate 3.1.x docs. You can change that in the API’s code by adding the following:
def custom_openapi():
if app.openapi_schema:
return app.openapi_schema
openapi_schema = get_openapi(
title="Sales API",
version="1.0.0",
description="API for retrieving sales data",
routes=app.routes,
)
# Set OpenAPI version
openapi_schema["openapi"] = "3.0.0"
# Add servers
openapi_schema["servers"] = [
{
"url": "https://REPLACE_THIS.ngrok-free.app", # Replace with your production URL
"description": "Production server"
}
]
# Add security scheme
openapi_schema["components"] = {
"securitySchemes": {
"BearerAuth": {
"type": "http",
"scheme": "bearer"
}
}
}
# Remove endpoint-specific security requirements
for path in openapi_schema["paths"].values():
for operation in path.values():
if "security" in operation:
del operation["security"]
app.openapi_schema = openapi_schema
return app.openapi_schema
app.openapi = custom_openapiIn the code, we switch to OpenAPI 3.0.0, add our server (the ngrok forwarding URL), add the security scheme and more. Now, when you go to https://your_ngrok_url/openapi.json, the JSON shown above should be returned.
Creating the Copilot Agent
Now we can create a new declarative agent like we did in the previous post. When you are asked for the OpenAPI document, you can retrieve it from the live server via the ngrok forwarding URL.
After creating the agent, declarativeAgent.json should contain the following action:
"actions": [
{
"id": "action_1",
"file": "ai-plugin.json"
}In ai-plugin.json, in functions and runtimes, you should see the function description and a reference to the OpenAPI operation.
That’s all fine but of course, but the API will not work because a key needs to be provided. You create the key in the Teams developer portal at https://dev.teams.microsoft.com/tools:

You create the key by clicking New API key and filling in the form. Ensure you add a key that matches the key in the API. Also ensure that the URL to your API is correct (the ngrok forwarding URL). With an incorrect URL, the key will not be accepted.

Now we need to add a reference to the key. The agent can use that reference to retrieve the key and use it when it calls your API. Copy the key’s registration ID and then open ai-plugin.json. Add the following to the runtimes array:
"runtimes": [
{
"type": "OpenApi",
"auth": {
"type": "ApiKeyPluginVault",
"reference_id": "KEY_REGISTRATION_ID"
},
"spec": {
"url": "apiSpecificationFile/openapi.json"
},
"run_for_functions": [
"get_sales_sales__get"
]
}
]The above code ensures that HTTP bearer authentication is used with the stored key when the agent calls the get_sales_sales__get endpoint.
Now you are ready to provision your agent. After provisioning, locate the agent in Teams:
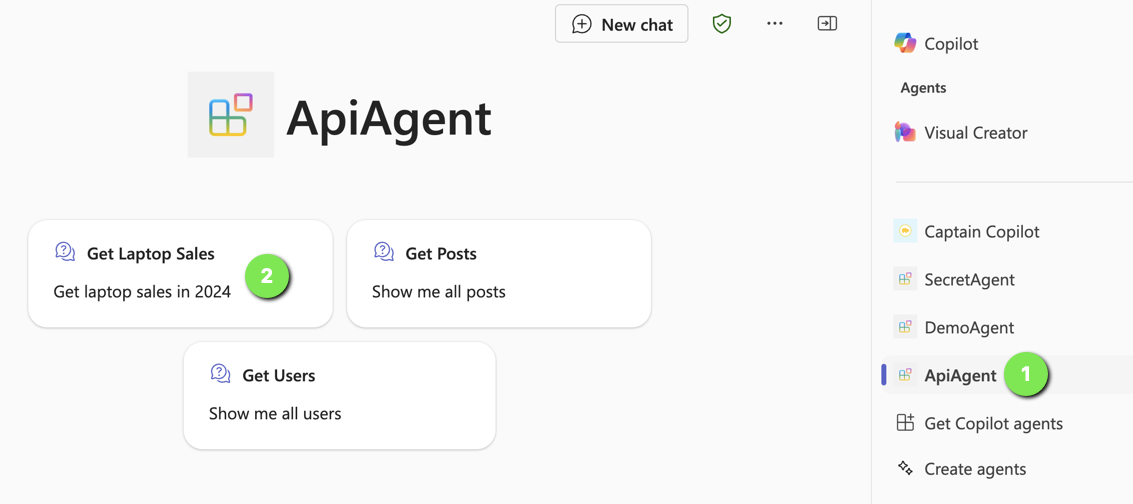
Now either use a starter (if you added some; above that is (2)) or type the question in the chat box.

Note that I did not do anything fancy with the adaptive card. It just says success.
If you turned on developer mode in Copilot, you can check the raw response:
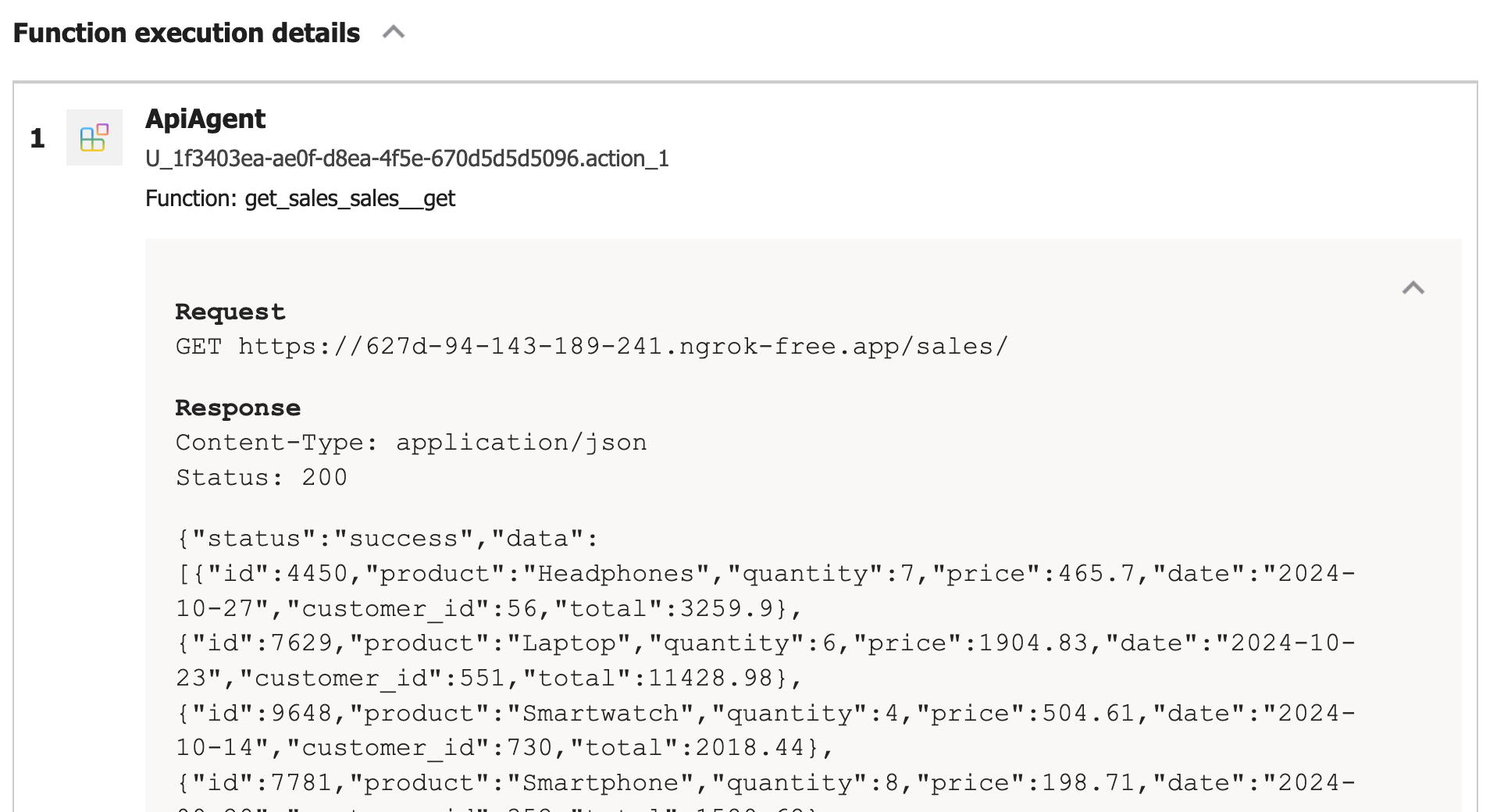
Conclusion
In this post, we created a Copilot agent that calls a custom API secured with HTTP bearer authentication. The “trick” to get this to work is to add the key to the Teams dev portal and reference it in the json file that defines the API call.
HTTP bearer authentication is the easiest to implement. In another post, we will look at using OAuth to protect the API. There’s a bit more to that, as expected.














 Microsoft has provided more details about Office 365 and the different identity options in a service description document (link at the bottom of this post).
Microsoft has provided more details about Office 365 and the different identity options in a service description document (link at the bottom of this post).



