In a previous blog post, we discussed two Python programs, upload_vectors.py and search_vectors.py. These programs were used to create and search vectors, respectively. The upload_vectors.py script created vectors from chunks of a larger text and stored them in Pinecone, while the search_vectors.py script enabled semantic search on the text. In this blog post, we will discuss how to create a user interface (UI) for these two programs using Streamlit.
🚀 I kickstarted the Streamlit app by handing over the text-based version to ChatGPT and asking it to work its magic ✨💻. Yes, it was that easy! Afterwards, I made several manual changes to make it look the way I wanted.
Pinecone, Vectors, Embeddings, and Semantic Search: What’s all that about?
Pinecone is a vector database service that allows for easy storage and retrieval of high-dimensional vectors. It is optimized for similarity search, which makes it a perfect fit for tasks like semantic search. Our script stores vectors in Pinecone by parsing an RSS feed, chunking the blog posts, and creating the vectors with OpenAI’s embedding APIs.
Vectors are mathematical representations of data in the form of an array of numbers. In our case, we use vectors to represent chunks of text retrieved from blog posts. These vectors are generated using a process called embedding, which is a way of representing complex data, like text, in a lower-dimensional space while preserving the essential information.
Semantic search is a type of search that goes beyond keyword matching to understand the meaning and context of the query. By using vector embeddings, we can compare the similarity between queries and stored texts to find the most relevant results. Pinecone does that search for us and simply returns a number of matching chunks (pieces of text).
What is Streamlit?
Streamlit is a Python library that makes it easy to create custom web apps for machine learning and data science projects. You can build interactive UIs with minimal code, allowing you to focus on the core logic of your application.
Here’s an example of creating an extremely simple Streamlit app:
import streamlit as st
st.title('Hello, Streamlit!')
st.write('This is a simple Streamlit app.')
This code would generate a web app with a title and a text output. You can also create more complex UIs with user input, like sliders, text inputs, and buttons.
Creating a Streamlit UI for Semantic Search
Now let’s examine the provided code for creating a Streamlit UI for the search_vectors.py program. The code can be broken down into the following sections:
- Import necessary libraries and check environment variables.
- Set up the tokenizer and define the
tiktoken_lenfunction. - Create the UI elements, including the title, text input, dropdown, sliders, and buttons.
- Define the main search functionality that is triggered when the user clicks the “Search” button.
Here is the full code:
import os
import pinecone
import openai
import tiktoken
import streamlit as st
# check environment variables
if os.getenv('PINECONE_API_KEY') is None:
st.error("PINECONE_API_KEY not set. Please set this environment variable and restart the app.")
if os.getenv('PINECONE_ENVIRONMENT') is None:
st.error("PINECONE_ENVIRONMENT not set. Please set this environment variable and restart the app.")
if os.getenv('OPENAI_API_KEY') is None:
st.error("OPENAI_API_KEY not set. Please set this environment variable and restart the app.")
# use cl100k_base tokenizer for gpt-3.5-turbo and gpt-4
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(
text,
disallowed_special=()
)
return len(tokens)
# create a title for the app
st.title("Search blog feed 🔎")
# create a text input for the user query
your_query = st.text_input("What would you like to know?")
model = st.selectbox("Model", ["gpt-3.5-turbo", "gpt-4"])
with st.expander("Options"):
max_chunks = 5
if model == "gpt-4":
max_chunks = 15
max_reply_tokens = 1250
if model == "gpt-4":
max_reply_tokens = 2000
col1, col2 = st.columns(2)
# model dropdown
with col1:
chunks = st.slider("Number of chunks", 1, max_chunks, 5)
temperature = st.slider("Temperature", 0.0, 1.0, 0.0)
with col2:
reply_tokens = st.slider("Reply tokens", 750, max_reply_tokens, 750)
# create a submit button
if st.button("Search"):
# get the Pinecone API key and environment
pinecone_api = os.getenv('PINECONE_API_KEY')
pinecone_env = os.getenv('PINECONE_ENVIRONMENT')
pinecone.init(api_key=pinecone_api, environment=pinecone_env)
# set index
index = pinecone.Index('blog-index')
# vectorize your query with openai
try:
query_vector = openai.Embedding.create(
input=your_query,
model="text-embedding-ada-002"
)["data"][0]["embedding"]
except Exception as e:
st.error(f"Error calling OpenAI Embedding API: {e}")
st.stop()
# search for the most similar vector in Pinecone
search_response = index.query(
top_k=chunks,
vector=query_vector,
include_metadata=True)
# create a list of urls from search_response['matches']['metadata']['url']
urls = [item["metadata"]['url'] for item in search_response['matches']]
# make urls unique
urls = list(set(urls))
# create a list of texts from search_response['matches']['metadata']['text']
chunk_texts = [item["metadata"]['text'] for item in search_response['matches']]
# combine texts into one string to insert in prompt
all_chunks = "\n".join(chunk_texts)
# show urls of the chunks
with st.expander("URLs", expanded=True):
for url in urls:
st.markdown(f"* {url}")
with st.expander("Chunks"):
for i, t in enumerate(chunk_texts):
# remove newlines from chunk
tokens = tiktoken_len(t)
t = t.replace("\n", " ")
st.write("Chunk ", i, "(Tokens: ", tokens, ") - ", t[:50] + "...")
with st.spinner("Summarizing..."):
try:
prompt = f"""Answer the following query based on the context below ---: {your_query}
Do not answer beyond this context!
---
{all_chunks}"""
# openai chatgpt with article as context
# chat api is cheaper than gpt: 0.002 / 1000 tokens
response = openai.ChatCompletion.create(
model=model,
messages=[
{ "role": "system", "content": "You are a truthful assistant!" },
{ "role": "user", "content": prompt }
],
temperature=temperature,
max_tokens=max_reply_tokens
)
st.markdown("### Answer:")
st.write(response.choices[0]['message']['content'])
with st.expander("More information"):
st.write("Query: ", your_query)
st.write("Full Response: ", response)
with st.expander("Full Prompt"):
st.write(prompt)
st.balloons()
except Exception as e:
st.error(f"Error with OpenAI Completion: {e}")
A closer look
The code first imports the necessary libraries and checks if the required environment variables are set, displaying an error message if they are not. The libraries you need are in requirements.txt on GitHub. You can install them with:
pip3 install -r requirements.txt
ℹ️ I recommend using a Python virtual environment when you install these dependencies; see poetry (just one example)
The tiktoken_len function calculates the token length of a given text using the tokenizer. This is used to display the tokens of each chunk of text we set to the ChatCompletion API. Depending on the model, 4096 or 8192 tokens are supported.
The UI is built using Streamlit functions, such as st.title, st.text_input, st.selectbox, and st.columns. These functions create various UI elements that the user can interact with to input their query and set search parameters. If you look at the code, you will see how easy it is to add those elements.
With the UI elements, you can set:
- the number of text chunks to return from Pinecone and to forward to the ChatCompletion API (using
st.slider) - the number of tokens to reply with (using
st.slider) - the model:
gpt-3.5-turboorgpt-4(ensure you have access to thegpt-4API) - the temperature (using
st-slider)
The options are shown in two columns with st.columns.
The main search functionality is triggered when the user clicks the “Search” button. The code then vectorizes the query, searches for the most similar vectors in Pinecone, and displays the URLs and chunks found. Finally, the selected model is used to generate an answer based on the chunks found and the user’s query. Often, gpt-4 will provide the best answer. It seems to be able to better understand all the chunks of text thrown at it.
Running the code
To run the code you need the following:
- A Pinecode API key and environment
- An OpenAI API key
It is easiest to run the code with Docker. If you have it installed, run the following command:
docker run -p 8501:8501 -e OPENAI_API_KEY="YOURKEY" \
-e PINECONE_API_KEY="YOURKEY" \
-e PINECONE_ENVIRONMENT="YOURENV" gbaeke/blogsearch
The gbaeke/blogsearch image is available on Docker Hub. You can also build your own with the Dockerfile provided on GitHub.
After running the image, go to http://localhost:8501 and first use the Upload page to create your Pinecode index and store vectors in it. You can use my blog’s feed or any other feed. You can experiment with the chunk size and chunk overlap.

You can add multiple RSS feeds one-by-one as long as you turn off Recreate index before each new upload. After you have populated the index, use the Search page to start searching:
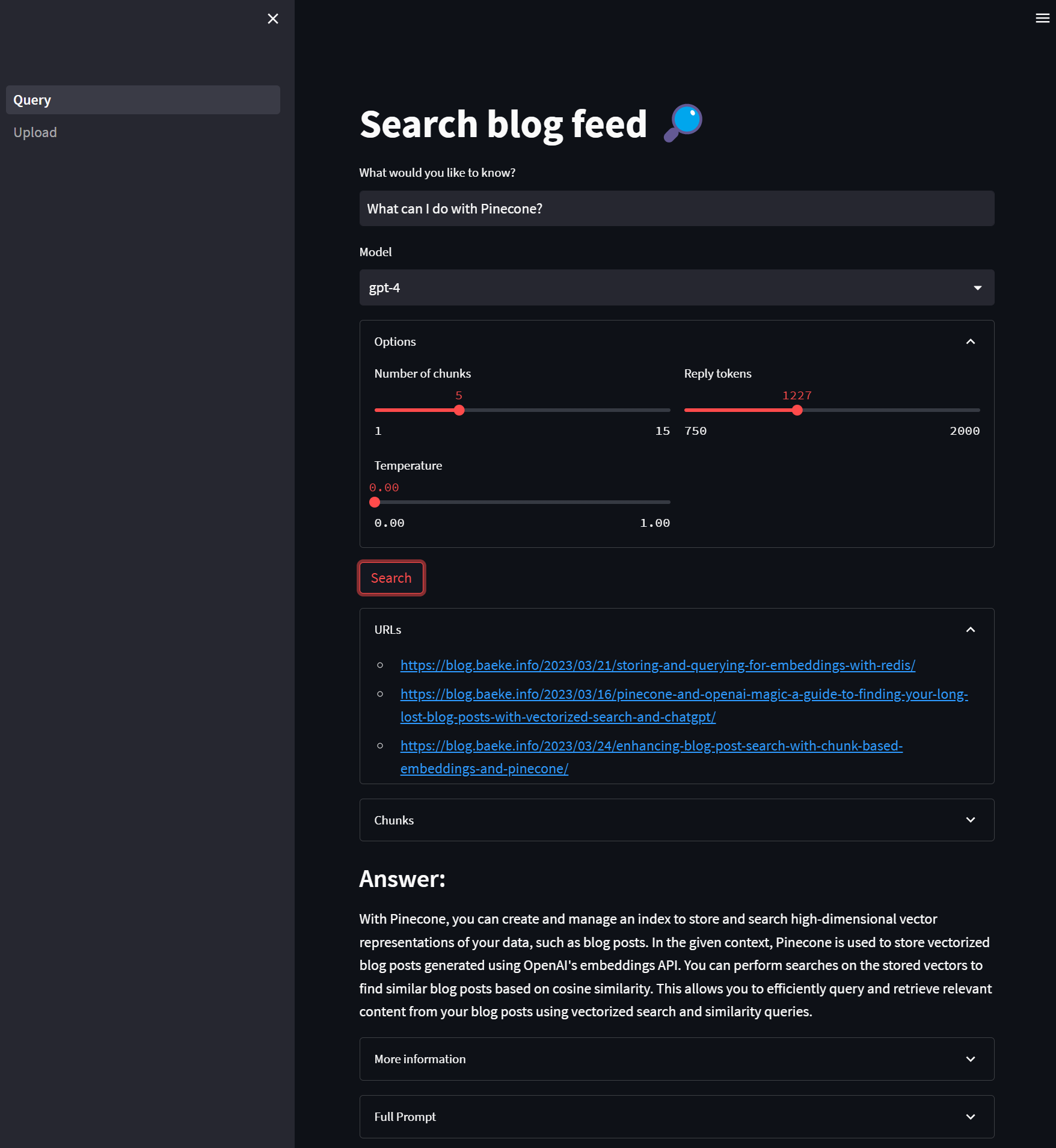
Above, we ask what we can do with Pinecone and let gpt-4 do the answering. The similarity search will search for 5 similar items and return them. We show the original URLs these results come from. In the Chunks section, you can see the original chunks because they are also in Pinecone as metadata. After the answer, you can find the full JSON returned by the ChatCompletion API and the full prompt we sent to that API.
Conclusion
In this blog post, we showed you how to create a Streamlit UI for the search_vectors.py script we talked about in a previous post. Streamlit allows you to easily build interactive web applications for your machine learning and data science projects. We also created a UI to upload posts to Pinecone. The full program allows you to add as much data as you want and query that data with semantic search, summarized and synthesized by the GPT model of choice. Give it a try and let me know what you think.